

How To Upload Data Into Hadoop Emr Cluster
An Introduction to Hadoop in EMR AWS.
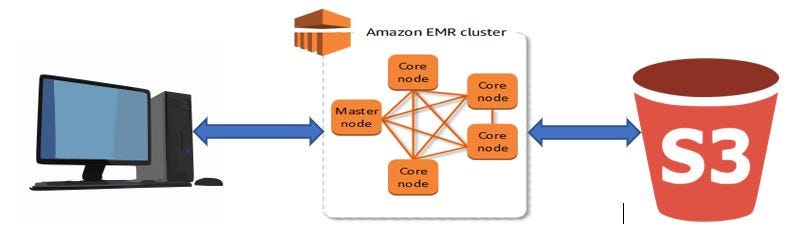
Big Data existence an integral role of Machine Learning, here we are going to process Freddie Mac Monthly Loan dataset stored in S3 using EMR. Hive is used to process the information and store the processed data in S3 for farther machine learning procedure. Sample dataset is having about i billion records. Beneath is an graphical representation of the activities to be performed.
Contents:
- Launch EMR Cluster and Empathize file systems.
- Transfer data between PC, S3, EMR Local and hdfs.
- Create Table in Hive, Pre-procedure and Load information to hive table.
- Data Assay and Optimization.
- Clone an existing tabular array.
- Complex and Cord Data Types.
- Working with Views.
- Bootstrap during launch of EMR cluster.
- Data transfer between HDFS and RDBMS.
Tools/Software Used:
- Storage — AWS S3.
- Processing — AWS EMR.
- Languages — FS Shell and HQL.
1. Launch EMR Cluster and Understand file systems :
Please follow the link to launch an EMR cluster and Connect to EMR using Git Bash(To be installed previously in local PC) and .pem file(Downloaded from AWS during user creation). Please enable Port 22 of EMR for admission.
In one case EMR is launched and continued, below is the screen for further playing with EMR.
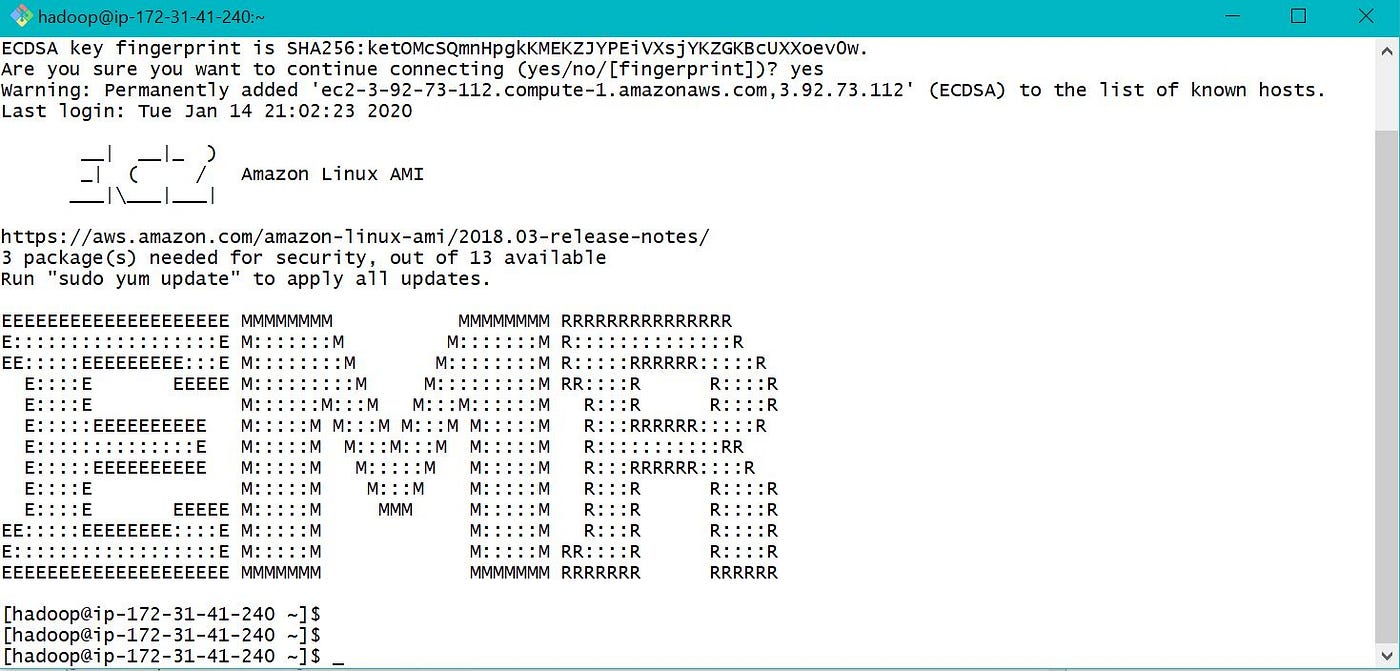
In EMR nosotros have both Local and Hadoop file systems. Below is the epitome showing default and newly created folders in Local and HDFS Folders.
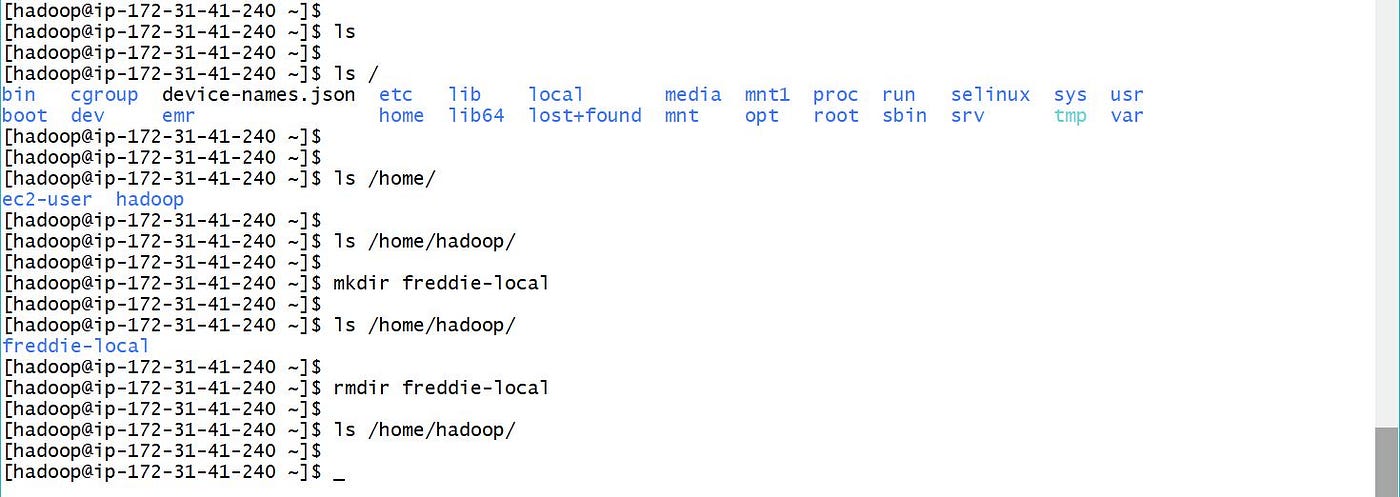
From higher up screen-prints, EMR local binder is /home/hadoop/. As we tin can see the test folder freddie-local was created in default folder /home/hadoop/.
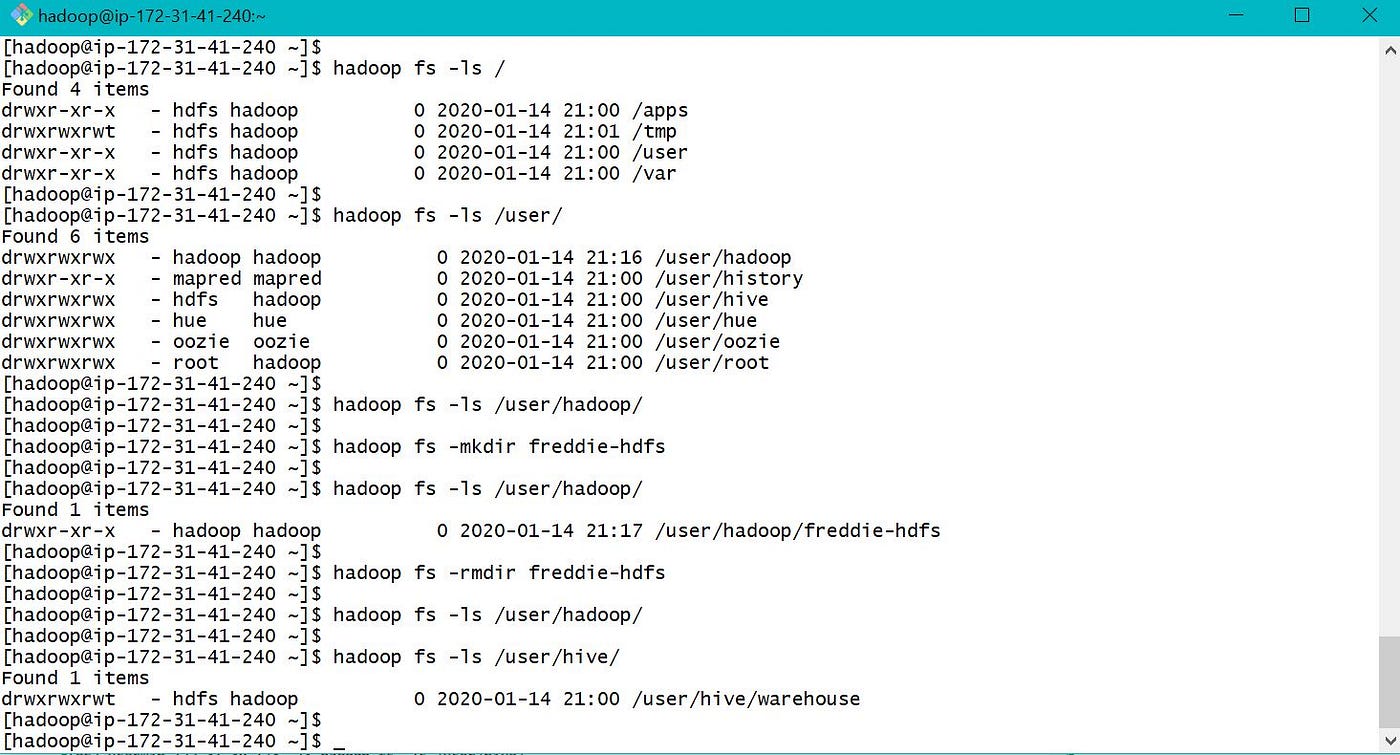
From to a higher place, EMR default HDFS folder is /user/hadoop/ as the test binder freddie-hdfs was created in location /user/hadoop/. Default hive folder is /user/hive/warehouse/. All the tables created in hive volition store data in default folder /user/hive/warehouse/ unless different LOCATION parameter is specified during table creation step. To access EMR Local, utilise only linux cli commands while to admission EMR HDFS we need to add together "hadoop fs" and "-" as shown above.
In AWS, "hive" command is used in EMR to launch Hive CLI as shown. Also we tin work with Hive using Hue. Please follow the link to launch Hue and access Hive.
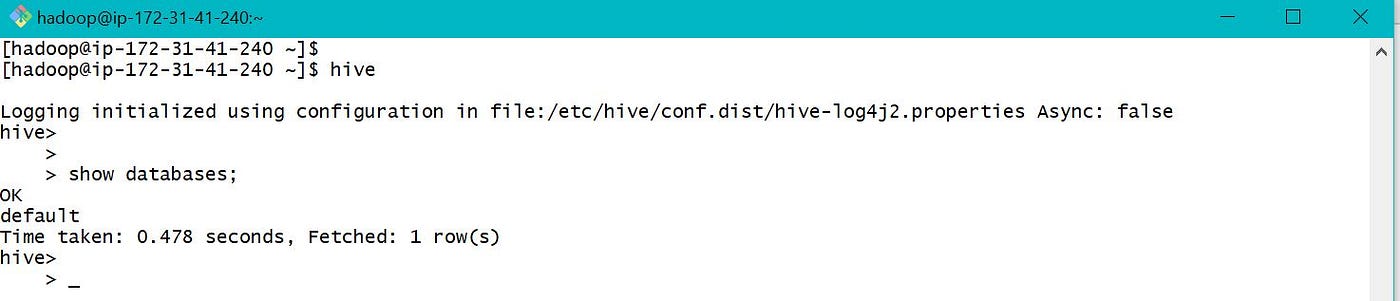
We are now all fix to play with Hive using CLI and Hue. In this story, we will apply Hive CLI for interacting with HDFS.
2. Transfer information between PC, S3, EMR Local and hdfs:
a. PC to EMR Local — Data tin can be transferred between PC and EMR Local using the commands every bit below. For connecting local PC to EMR cluster, .pem file is required which should exist created during user creation. Hither nosotros volition transfer a test file freddie-mac.txt from desktop to EMR local.
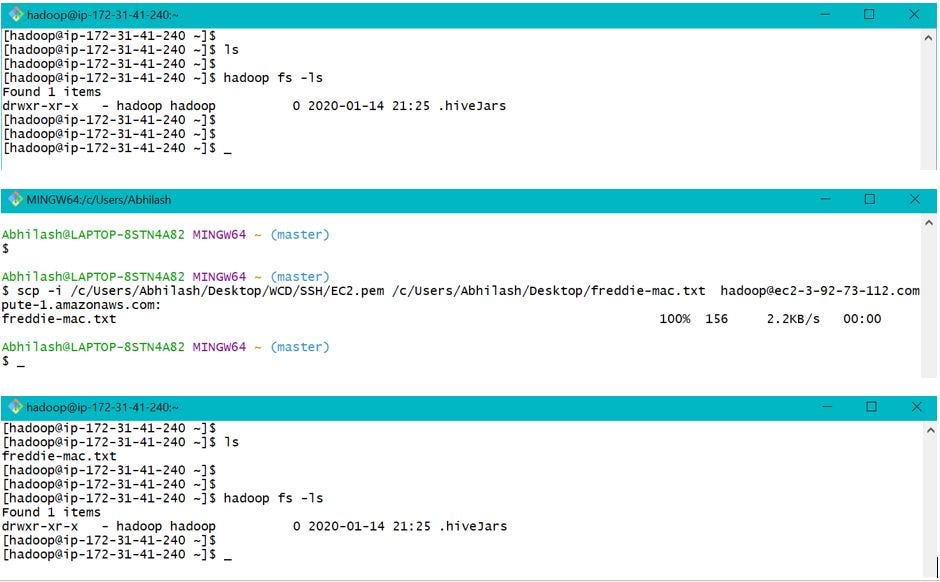
b. S3 to EMR local — "aws s3 cp" and "curl" tin exist used to move information between S3 and EMR local as beneath. Hither we will transfer file freddie-mac.txt from S3 bucket freddie-mac-hgsh to EMR local folder i.due east /abode/hadoop/.
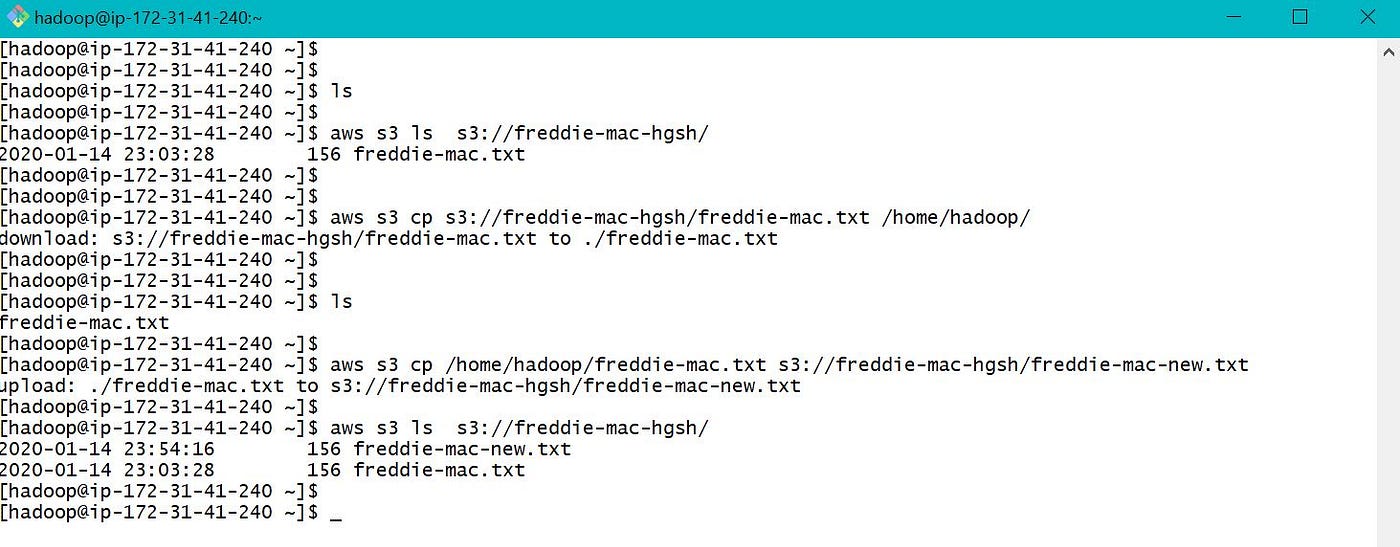
We can besides apply "hadoop fs -get" to pull and "hadoop fs -put" to button data betwixt S3 and EMR local as below.
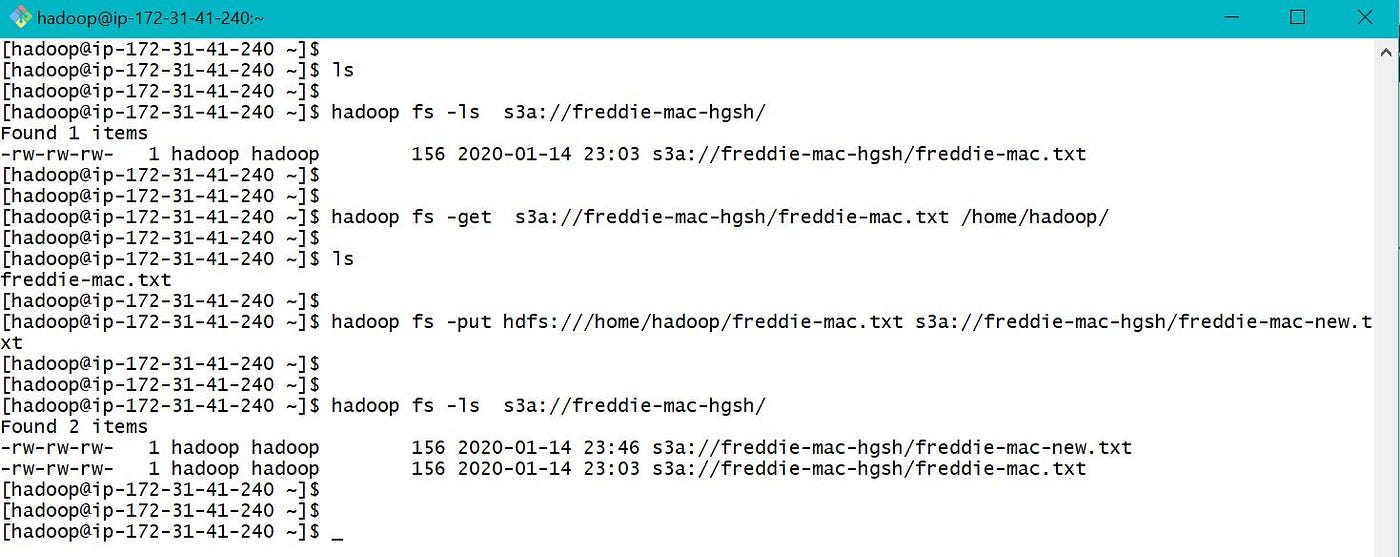
Scroll can also be used to download data from S3 to EMR local every bit below.
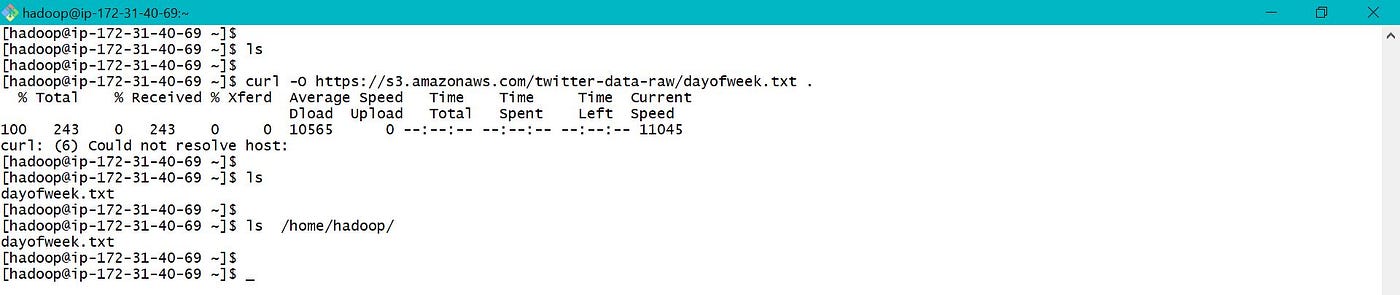
c. EMR Local to hdfs — "hadoop fs -put" and "hadoop fs -get" can be used to move data between EMR Local and hdfs every bit below.
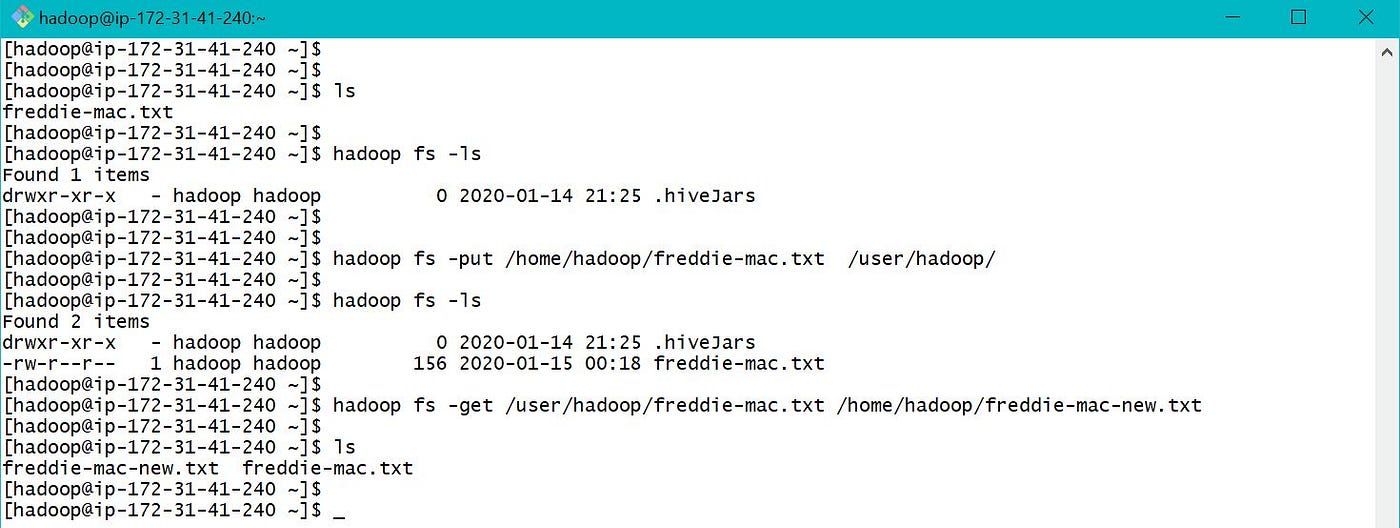
d. S3 to EMR Hdfs — "hadoop fs -cp" can be used to move data between S3 and EMR hdfs as below.

eastward. Browse files in S3 and Hdfs — "hadoop fs -cat" can exist used to browse information in S3 and EMR Hdfs as below. Here head along with "|" character is used to limit the number of rows.
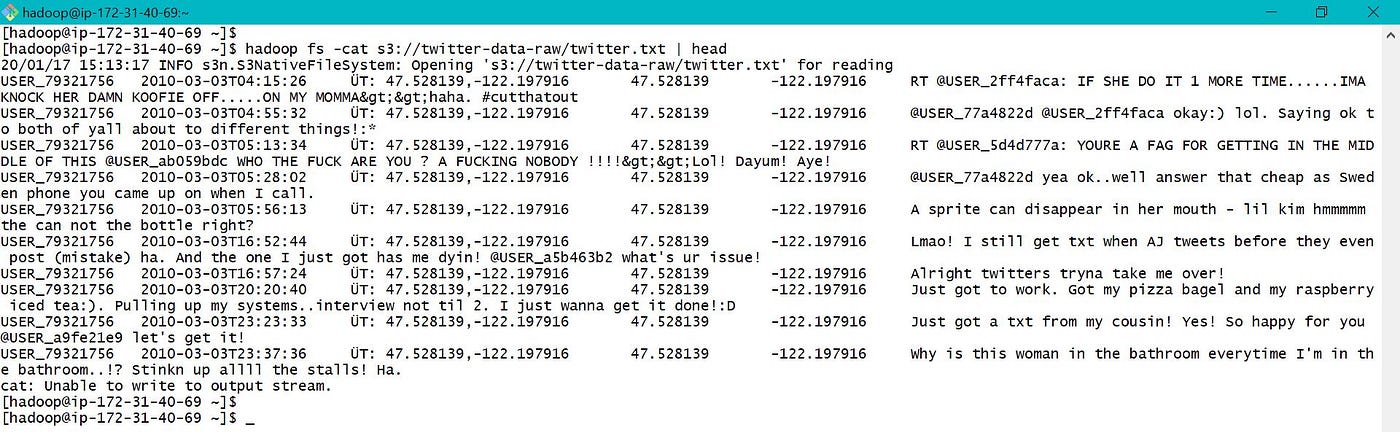
Information was copied from EMR local to hdfs and browsed as shown beneath.

3. Create Table in Hive, Pre-procedure and Load data to hive table:
In hive nosotros can create external and internal tables. For external tables, data is not deleted when a table is deleted. Its only schema which is deleted. For internal tables, both data and schema are deleted when a table is deleted.
When a table is created in hive, /user/hive/warehouse/ is default location where tabular array data is stored. But nosotros can also specify unlike location for table data to exist stored or referenced while creating a table. The information location can be any folder in EMR HDFS /user/* or S3.
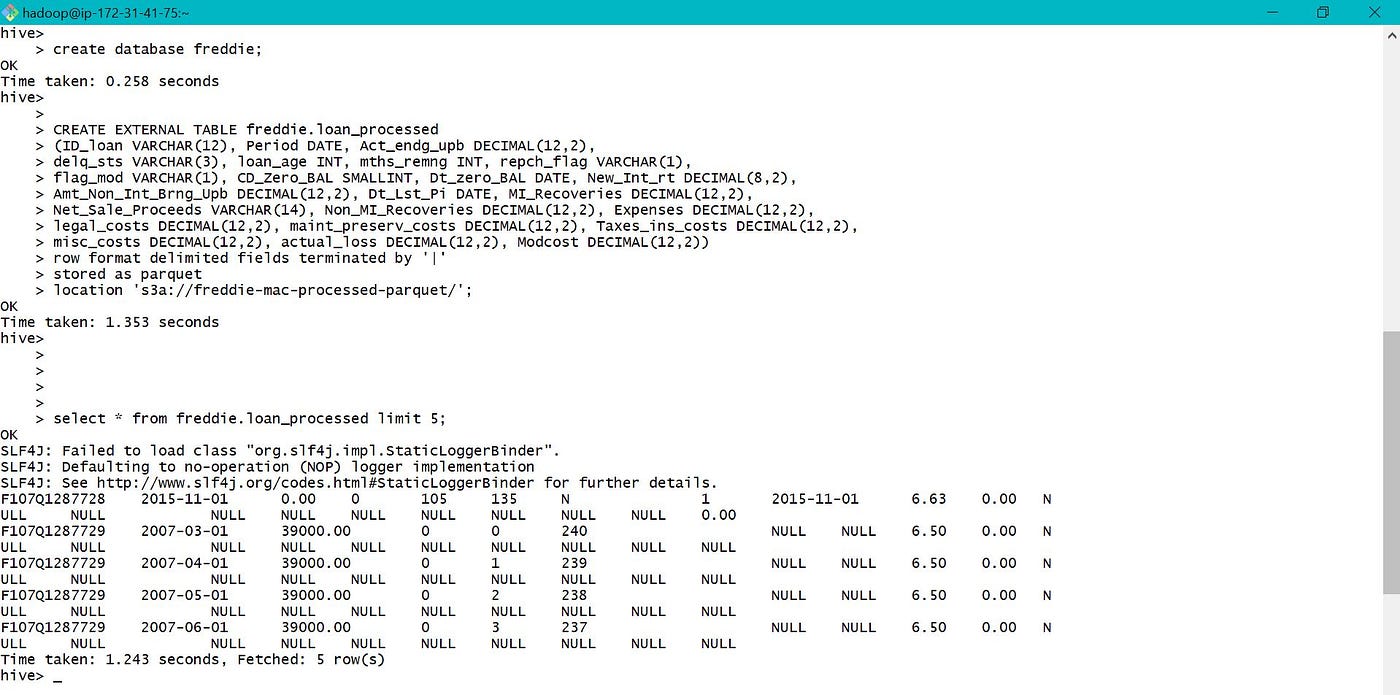
In current projection, we have raw data in parquet format stored at S3. We need to process and store final data in S3, for farther machine learning process. Then nosotros practise not demand to store table data into hdfs and also our data should be retained even after we terminate our EMR cluster. Hence volition create an external table and use location as S3 bucket.
The respective schema was created using freddie mac reference document (Monthly Performance Data File). Accept collected the raw data file and stored in S3. The last three fields pace modification flag, deferred payment modification and estimated loan to value (ELTV) are excluded from the raw input file.
Please refer beneath screen prints for creating external table using raw data stored in S3.




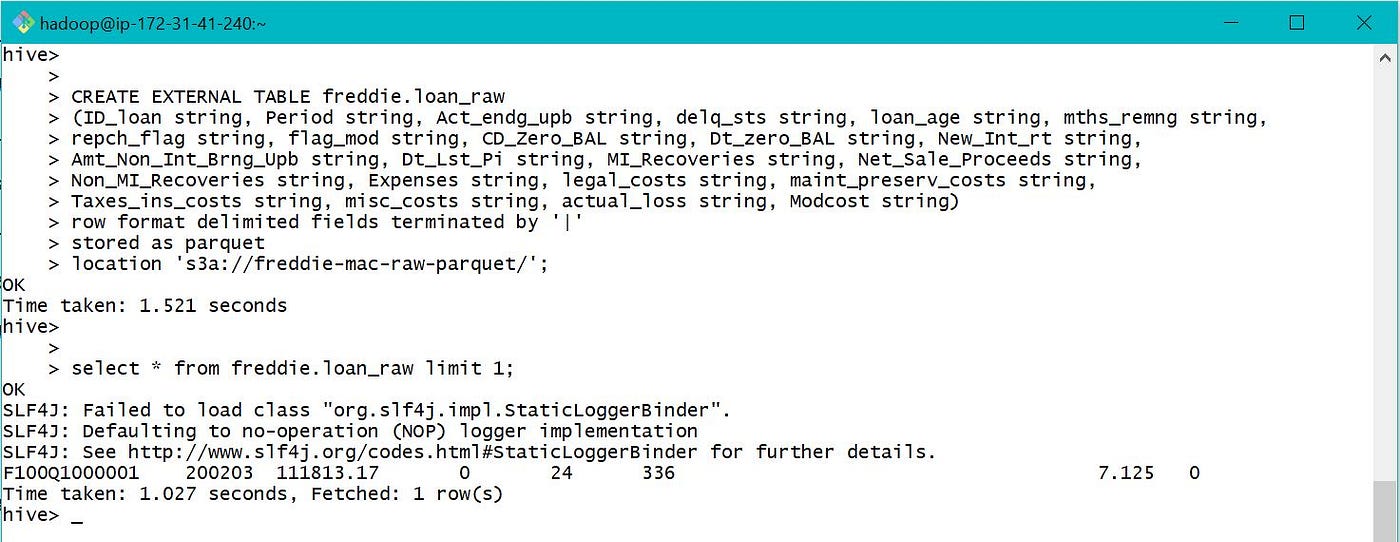
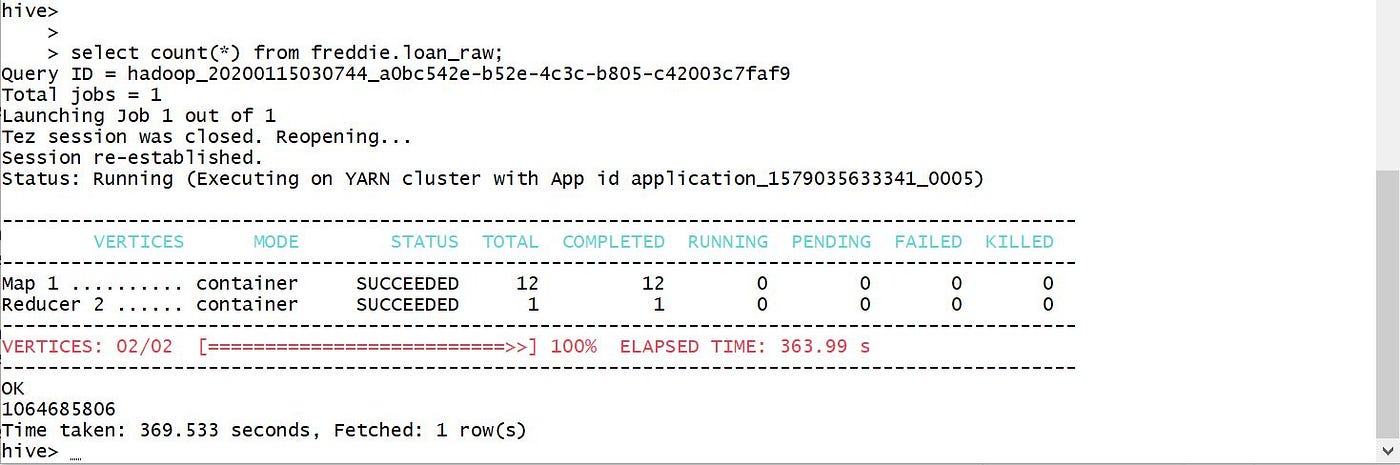
Please refer beneath screen-prints for creating external table to store candy information in S3 and load data into the table.
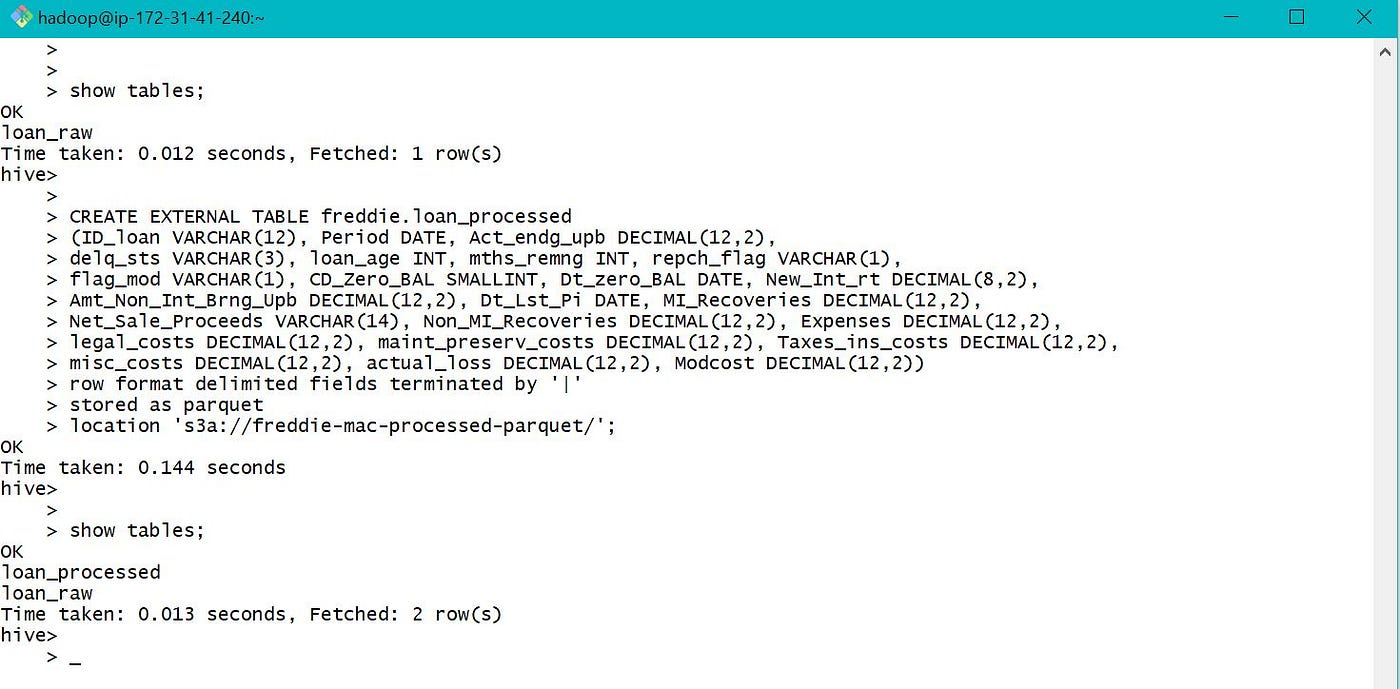
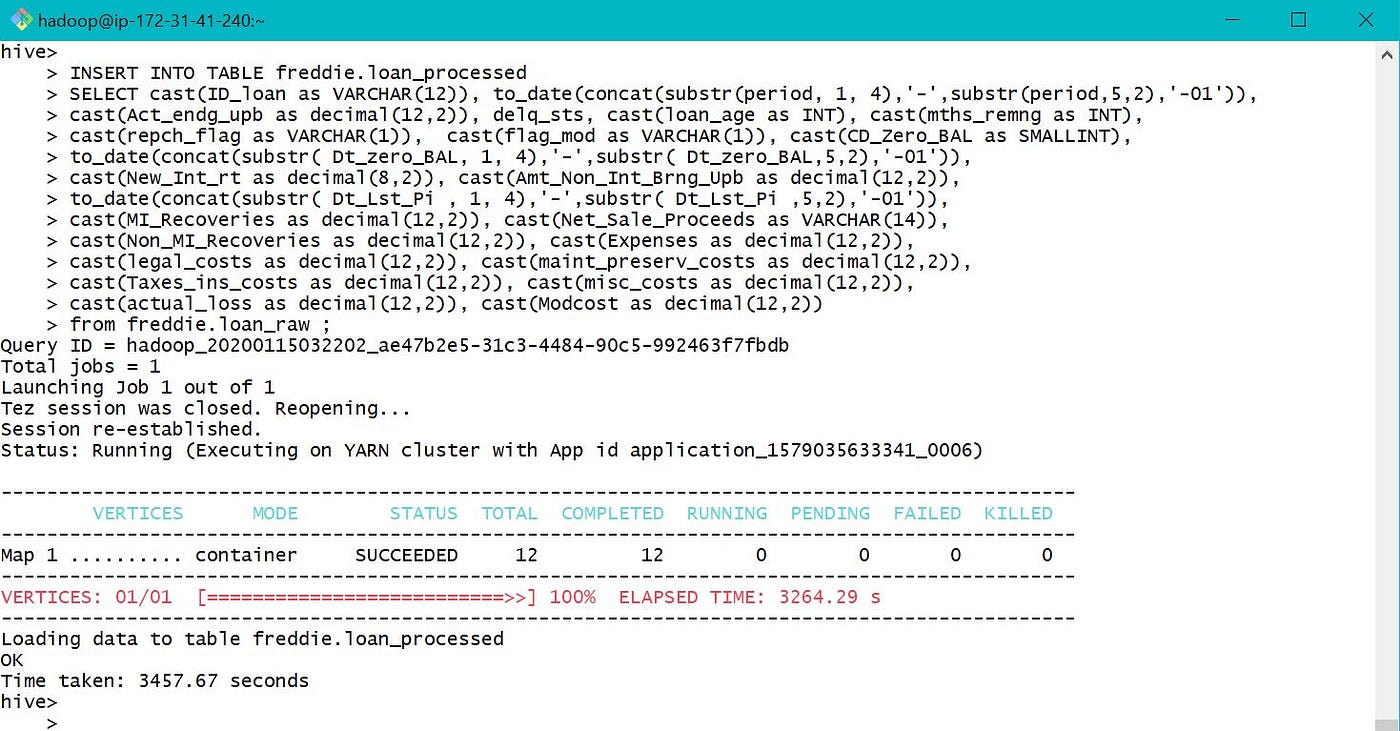
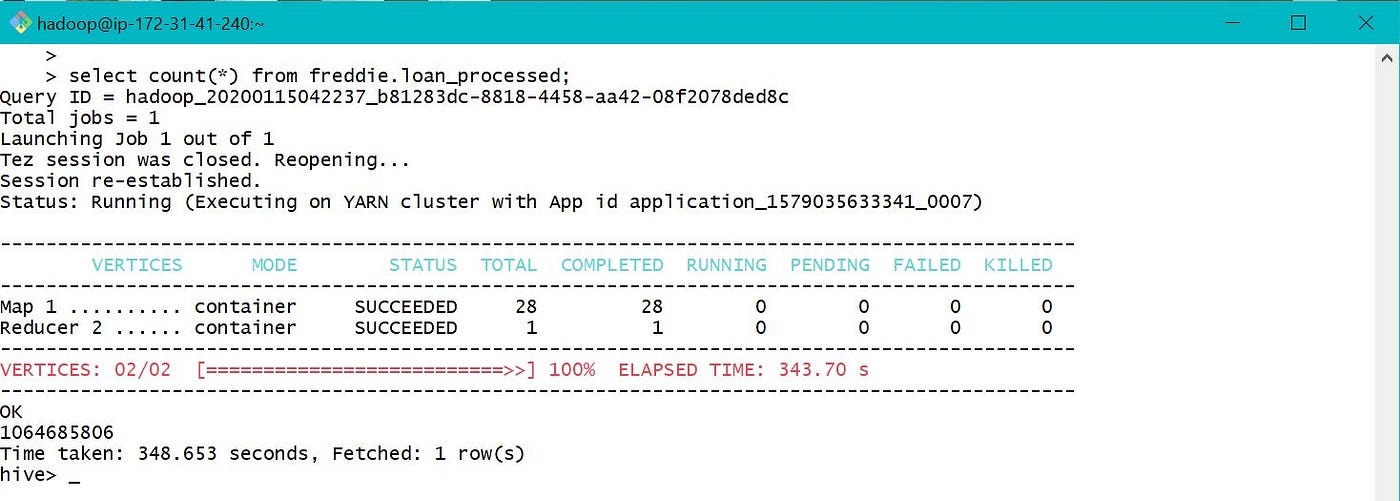
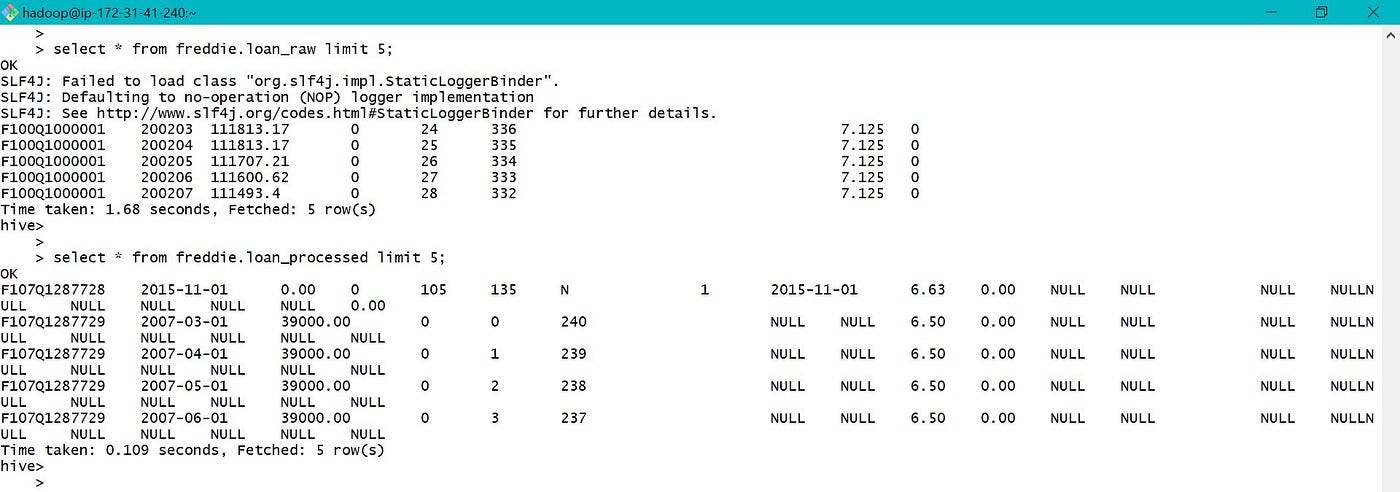
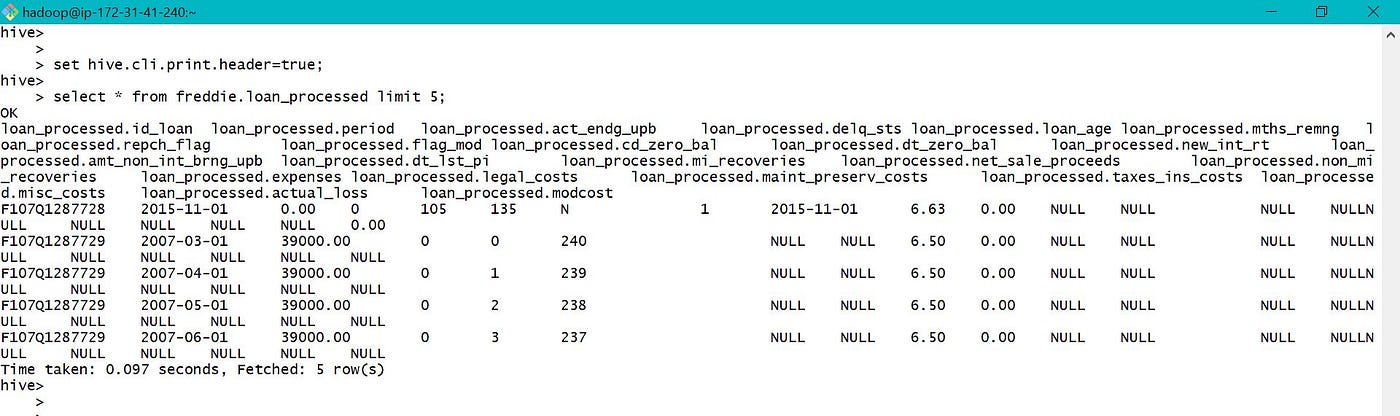
As the table location was provided every bit ane of the S3 bucket, o/p was written to S3 bucket instead of default location /user/hive/warehouse/ every bit below.
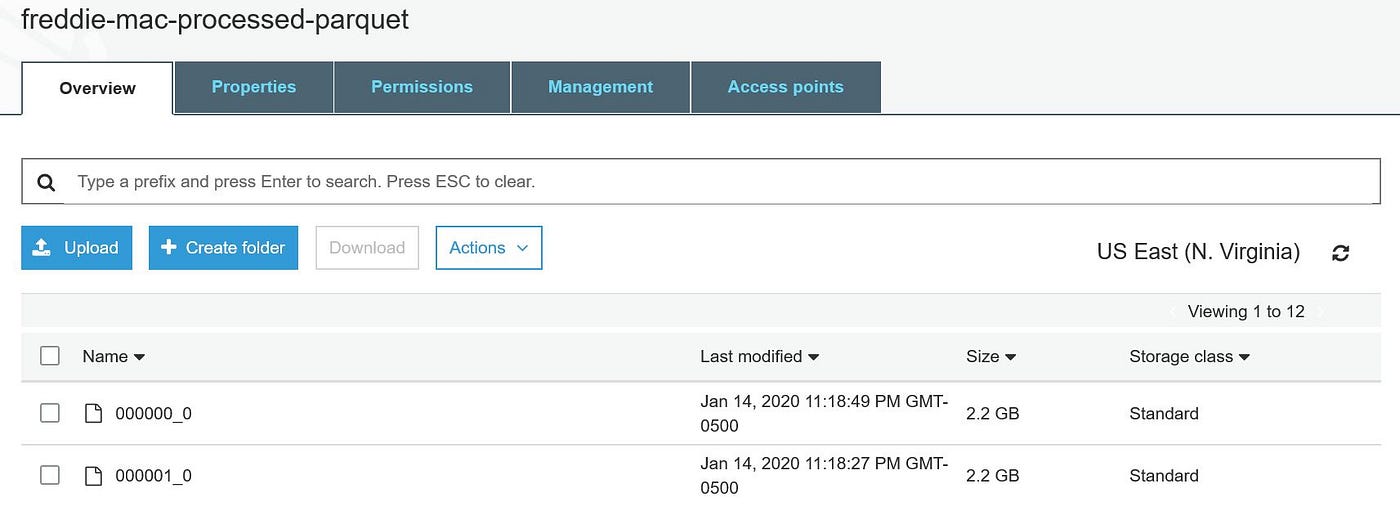
Once the above processing is done, will terminate the EMR cluster and volition launch a new one later for further assay and processing.
4. Data Analysis and Optimization:
A new EMR cluster was launched every bit described previously. Two carve up GIT fustigate CLI were used, one to connect with hadoop and the other to hive. Once connected to hive, volition create a new database and a table using the processed information created earlier in S3.

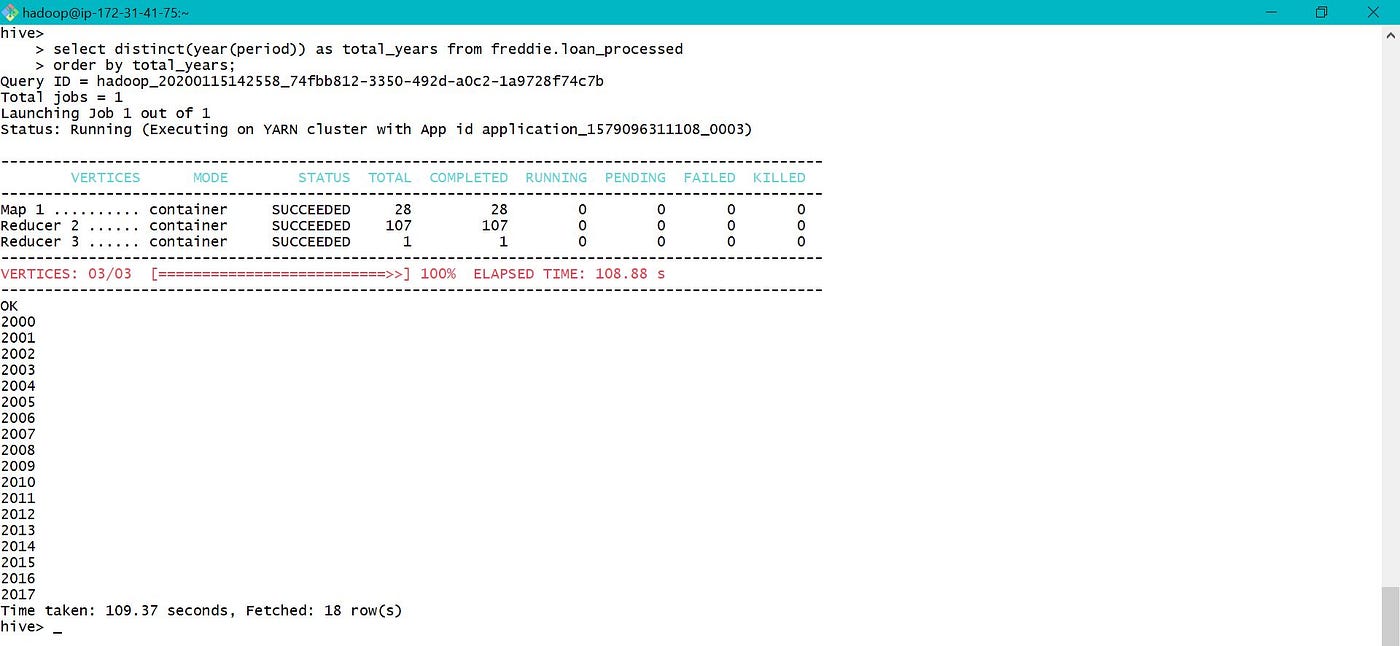
a. Data is having records from 2000 to 2017 as shown below.
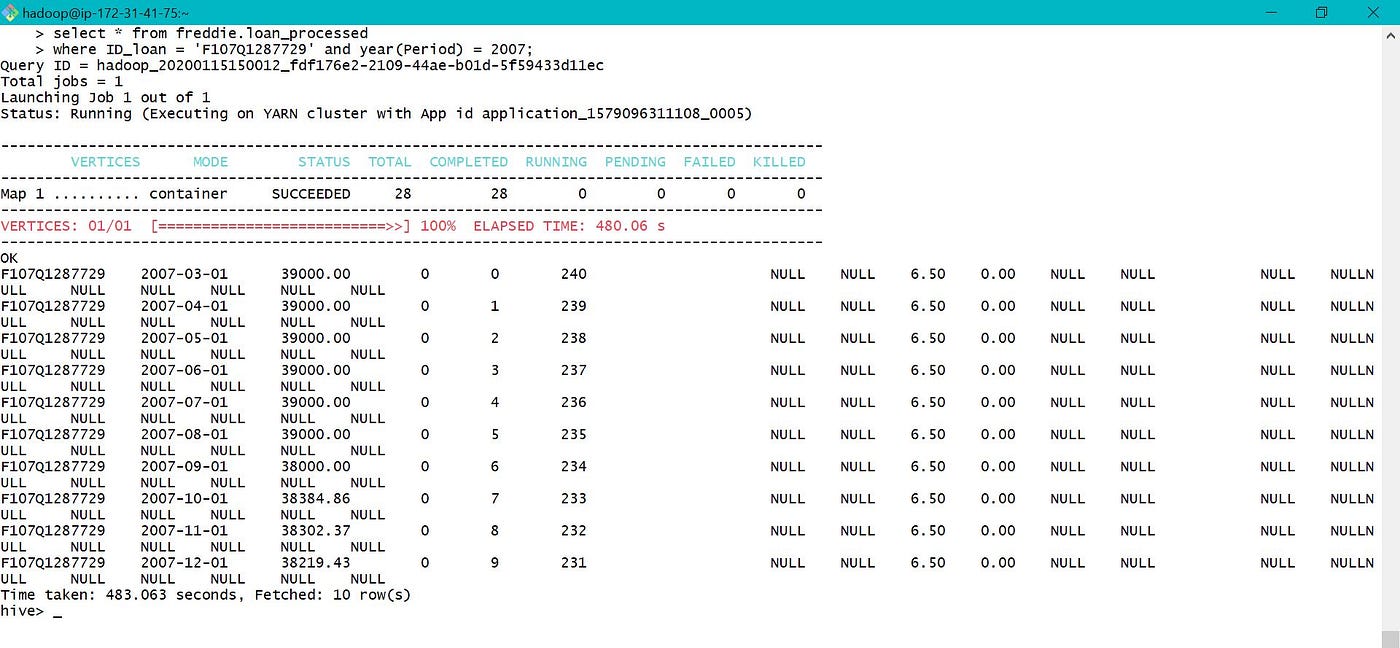
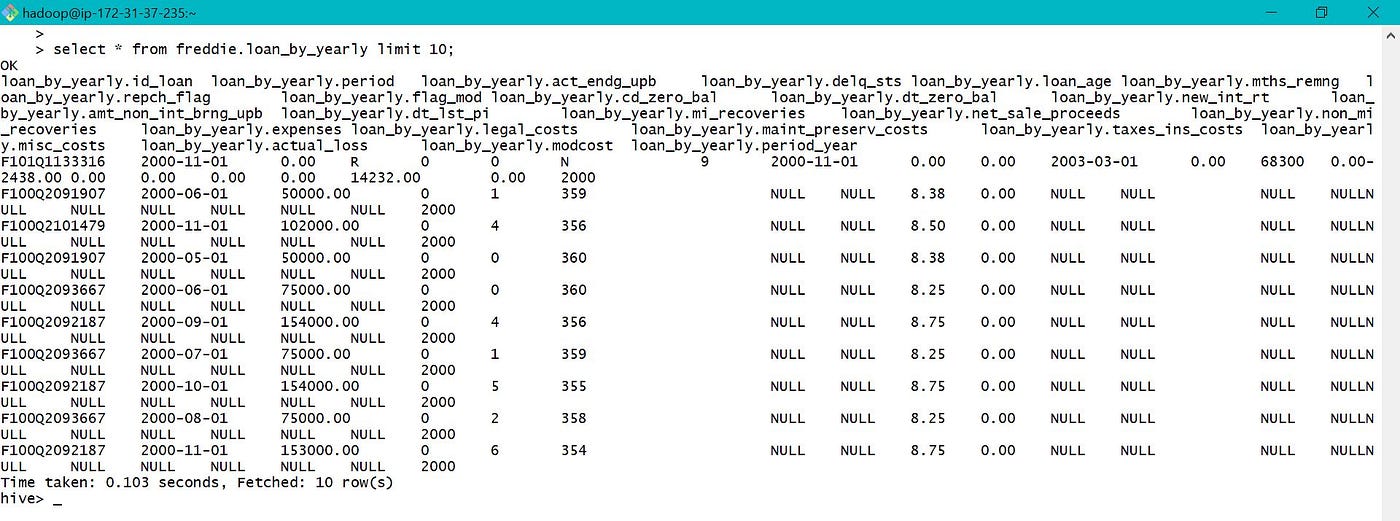
b. Selecting all the monthly functioning data for Loan ID F107Q1287729 in year 2007.
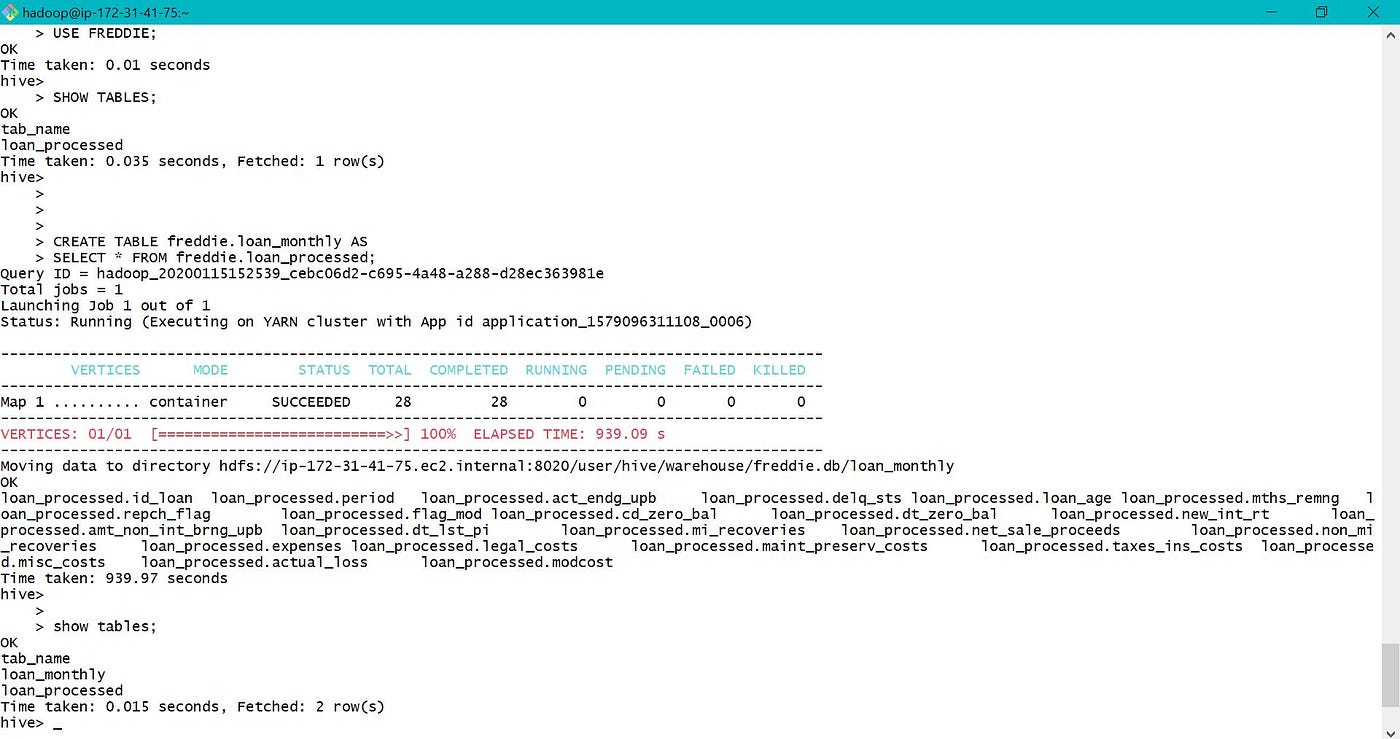
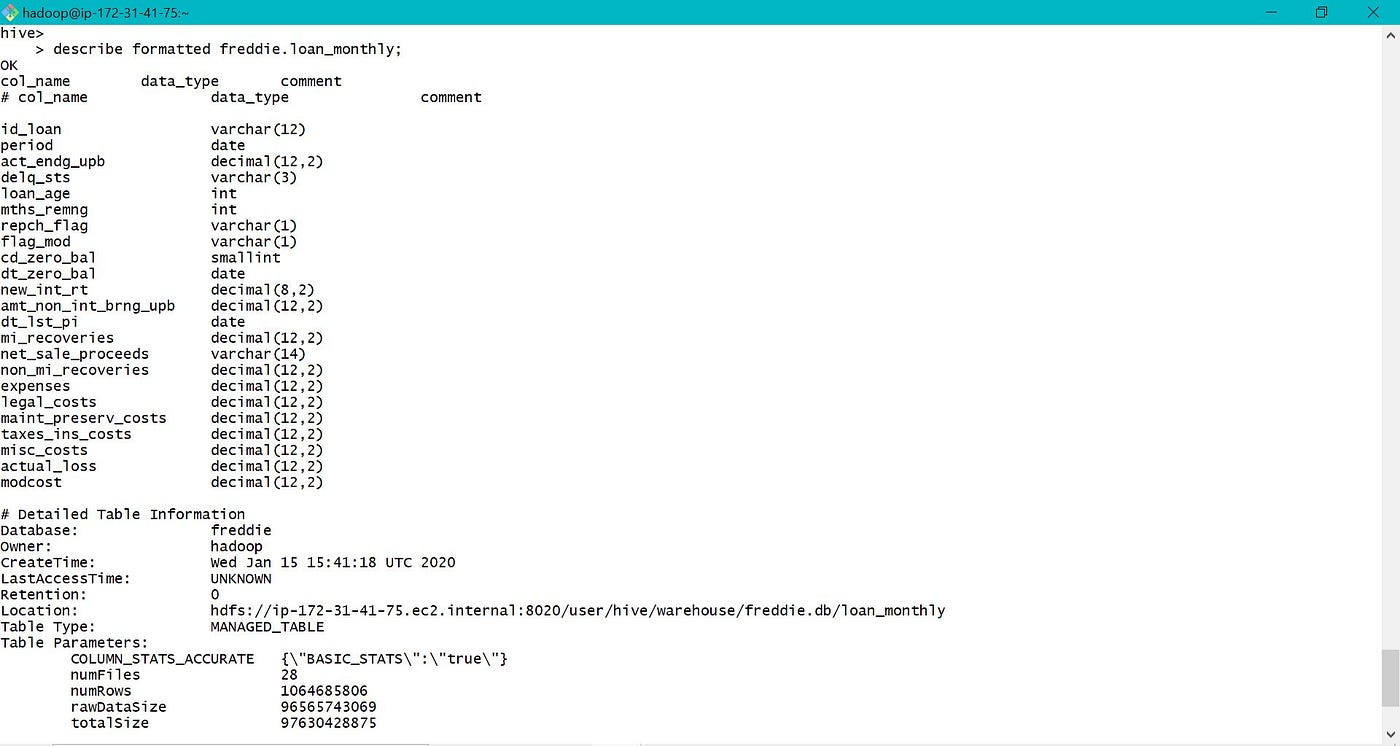
c. For all the above queries, data is fetched from S3 equally the specified table data location is S3 bucket. Instead of using S3, nosotros can also move the data into hive past creating another table as show below for further processing.


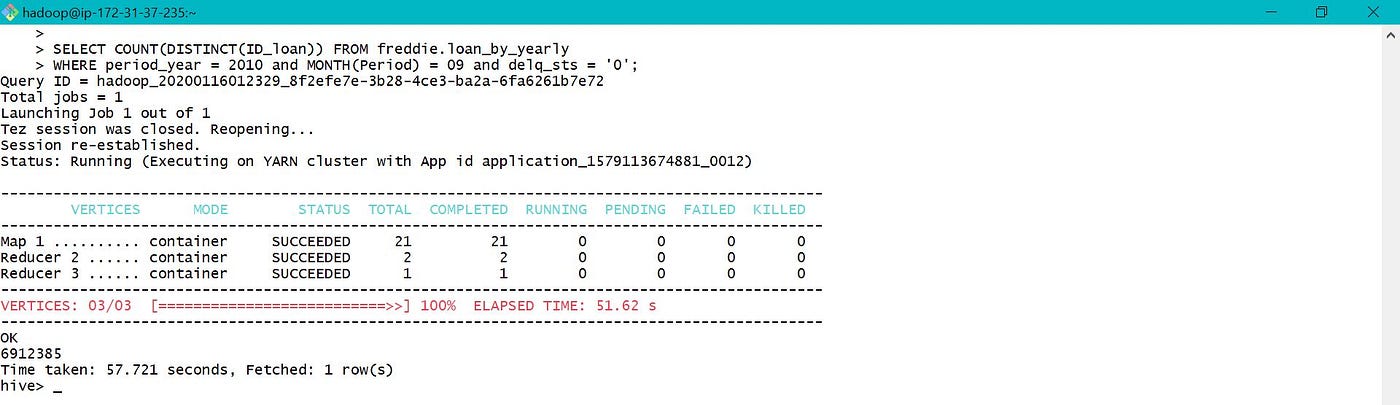
d. Find count of loan id with electric current loan delinquent status = 0(Runaway less than 30 days) on month of September 2010.
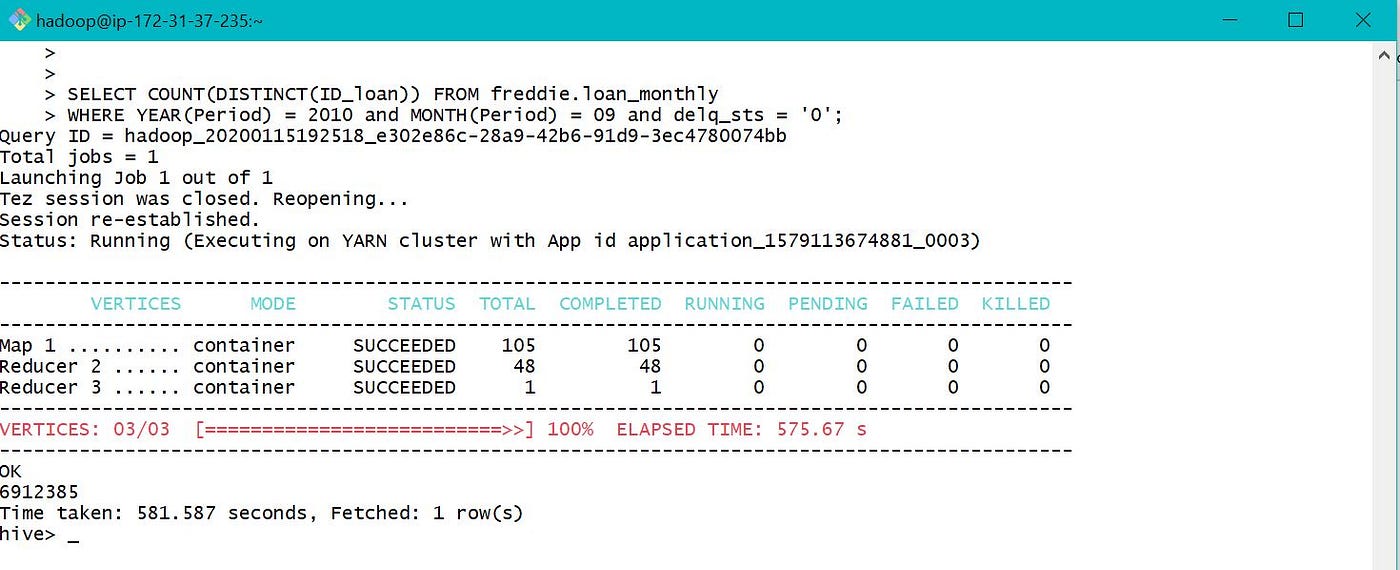
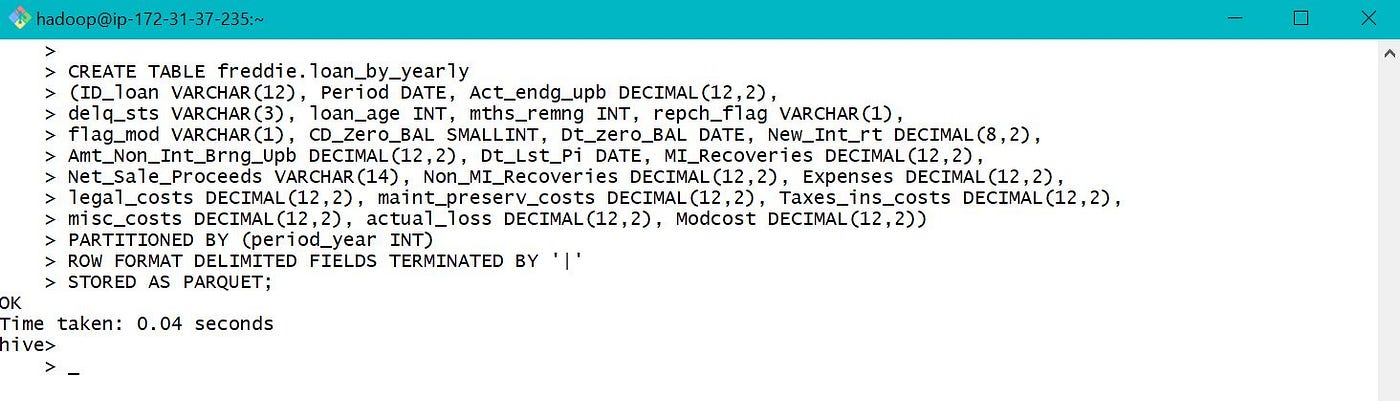
e. One way of optimizing hive queries is creating Partitioned Tables. Table Partitions are created based on the common blazon of queries being performed over the tabular array. If this is not done carefully, may be more costly. Here nosotros presume that our data is mostly queried based on Date or Year. Hence creating a partitioned table for optimization. This is dynamic partitioning, as partitions are created from certain data field for each row.


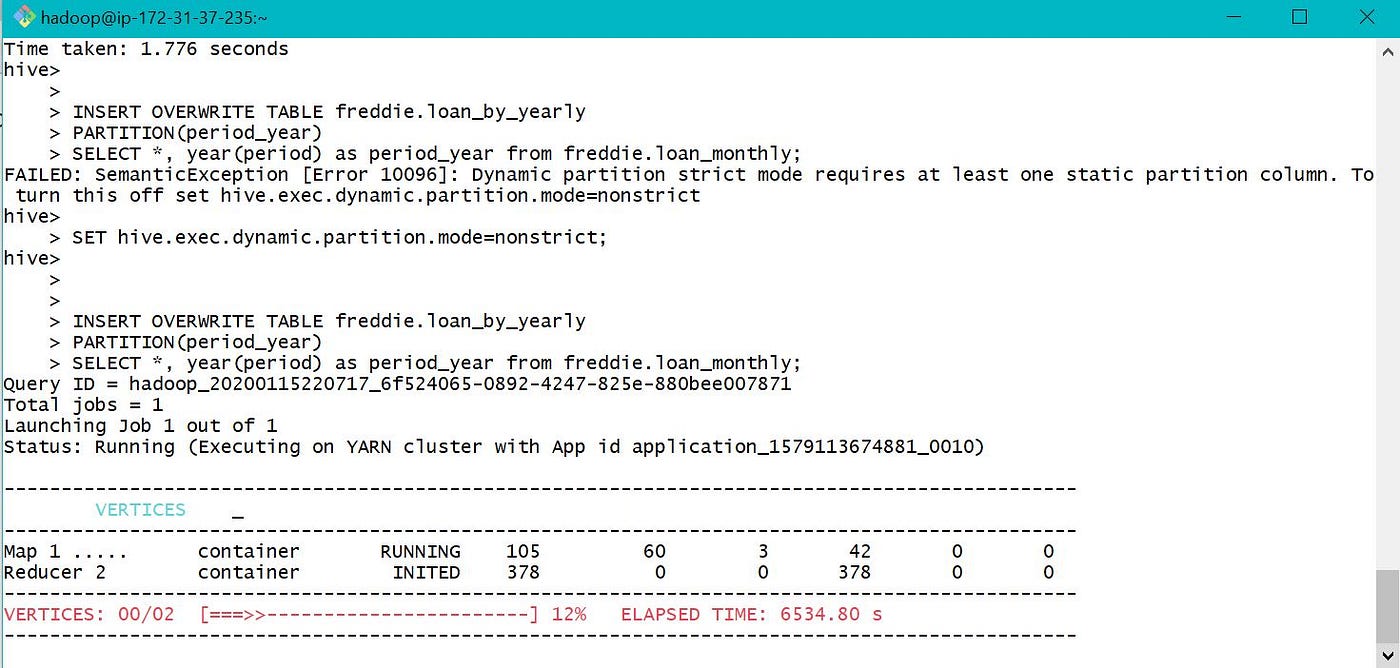
After visiting YARN, found out like in that location was no container allocated to chore.
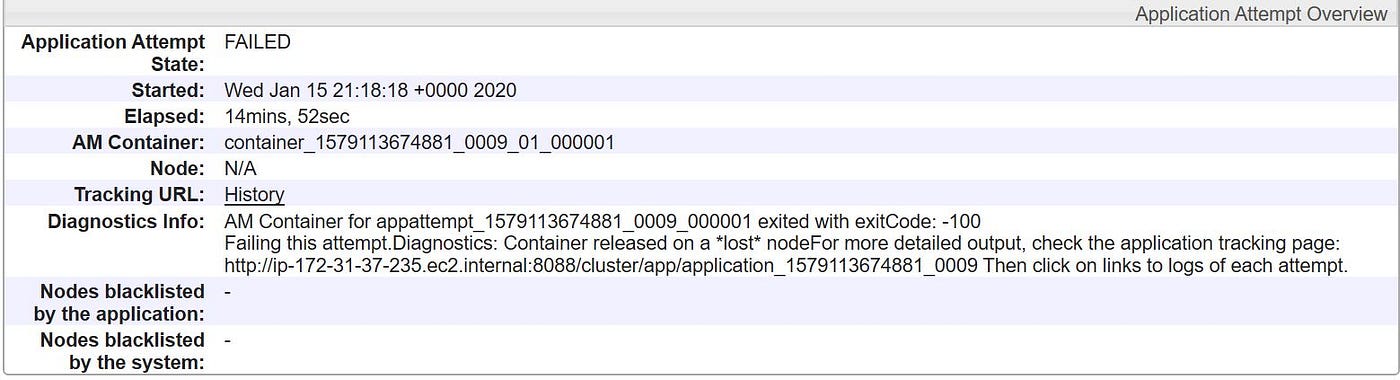

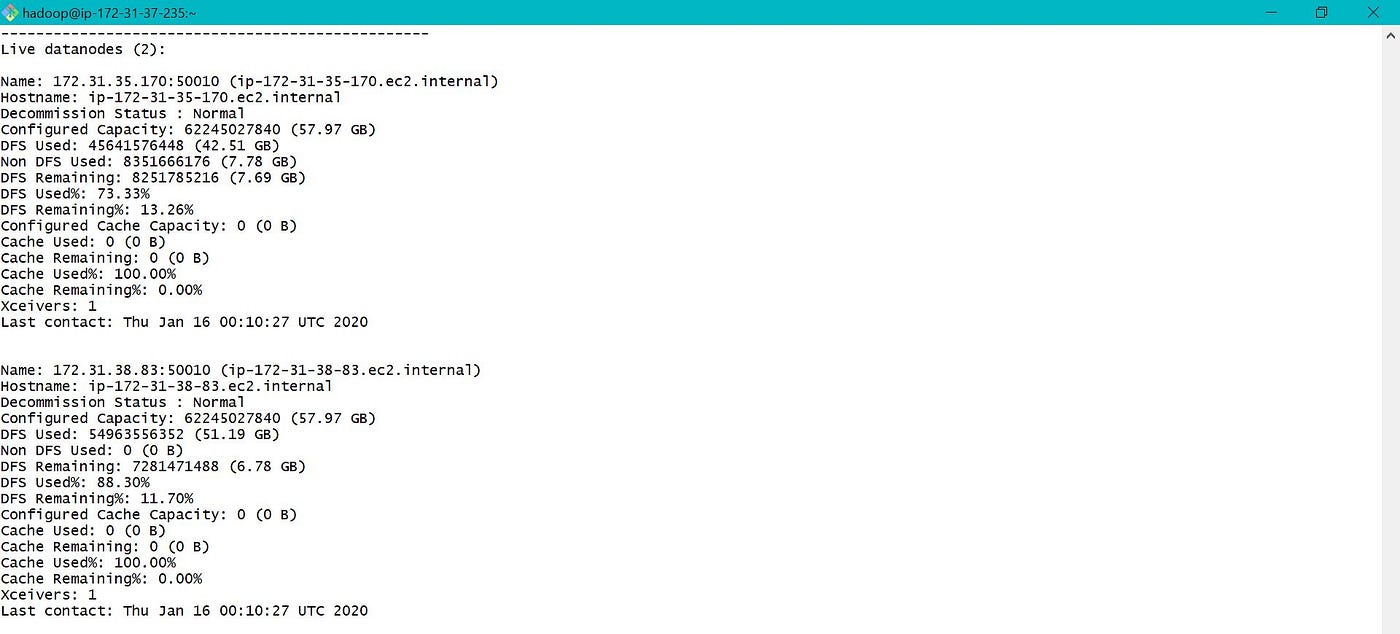
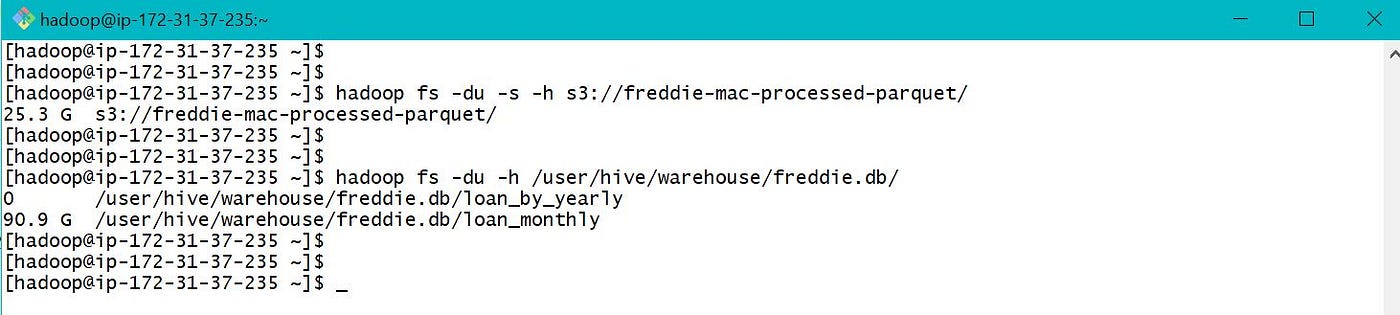
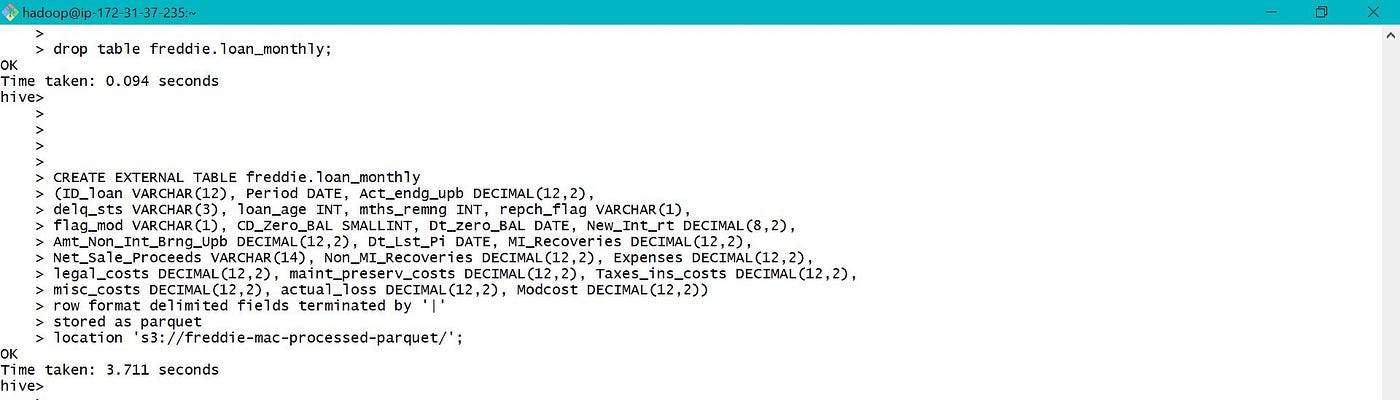
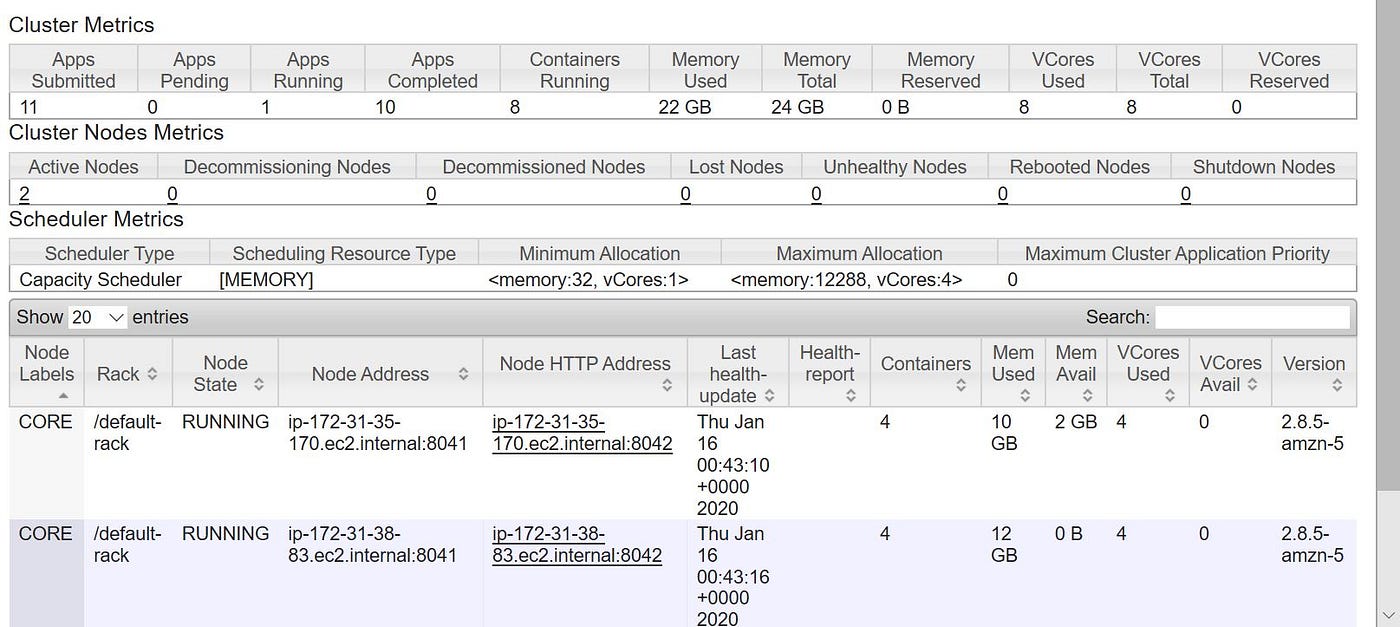
Due to limited memory in my EMR cluster, deleted table loan_monthly and created a new External Tabular array loan_monthly with data location as S3 bucket. Used the external table to load data into partitioned tabular array loan_by_yearly. Along with the link, below are few screen prints depicting YARN and Cluster Nodes while data was loaded.
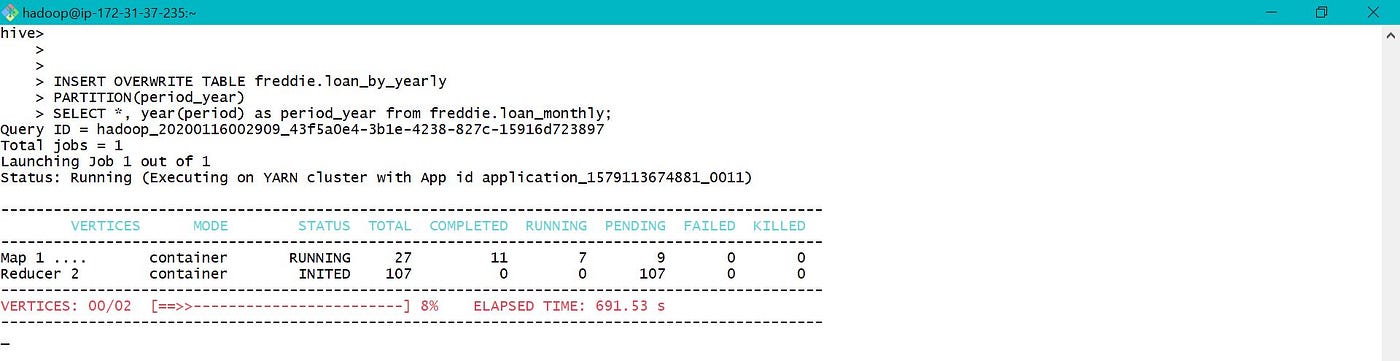
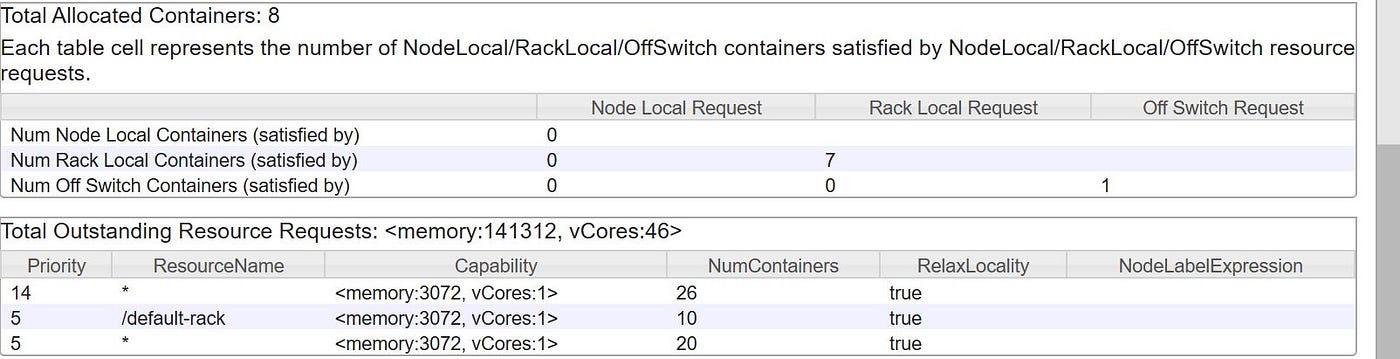
As we allocated but two cadre nodes while creating EMR cluster, but two of them were used while loading data into partitioned tabular array.
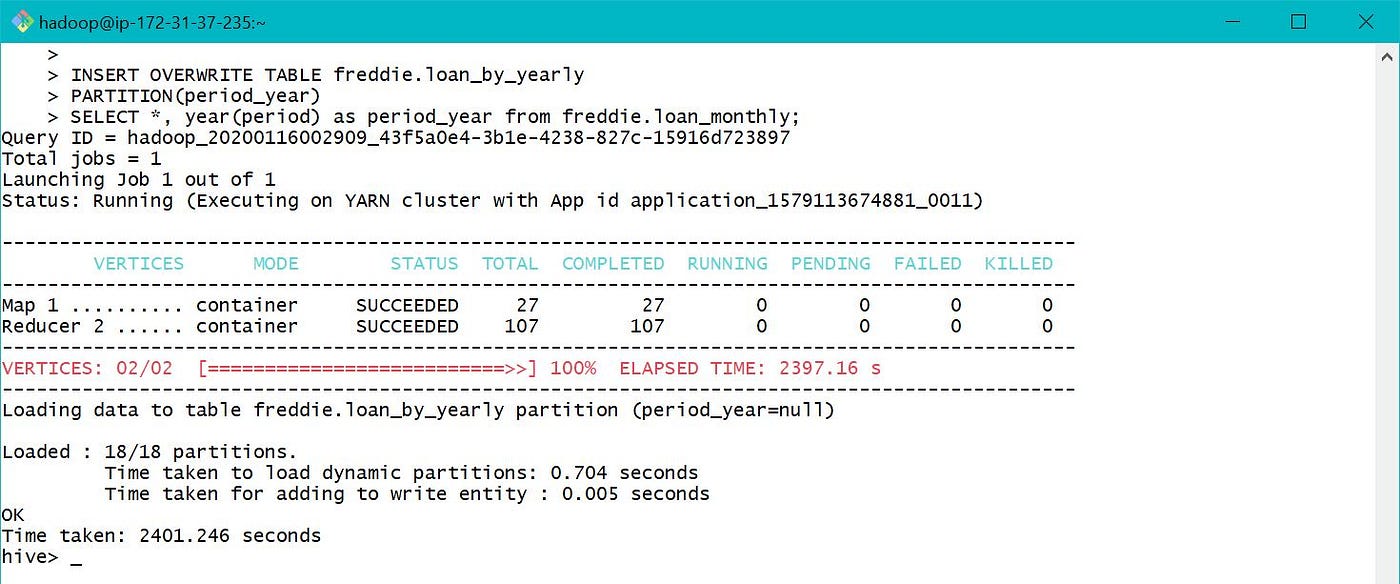
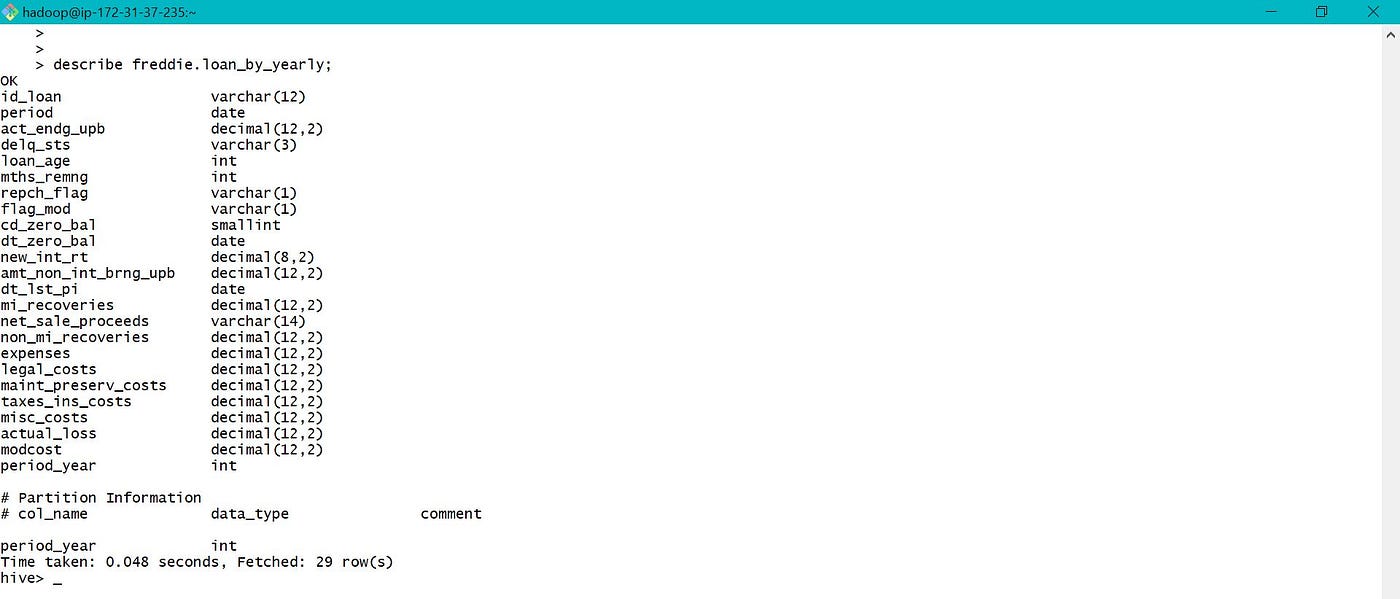
Sub folders are created based on the value of period_year based on which sectionalization was done.
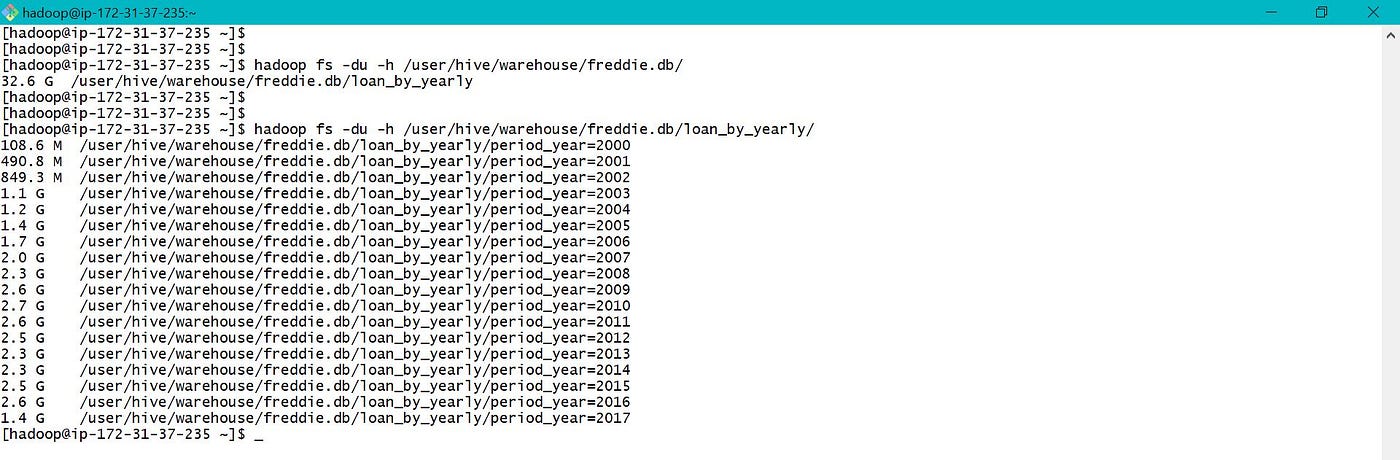
The parameter by which table is partitioned appears as a cavalcade when table is viewed or used, but is not actually added to data file.
After executing the same query as earlier, it costed only 52 secs instead of 575 secs which is nigh 10 times efficient in this case.
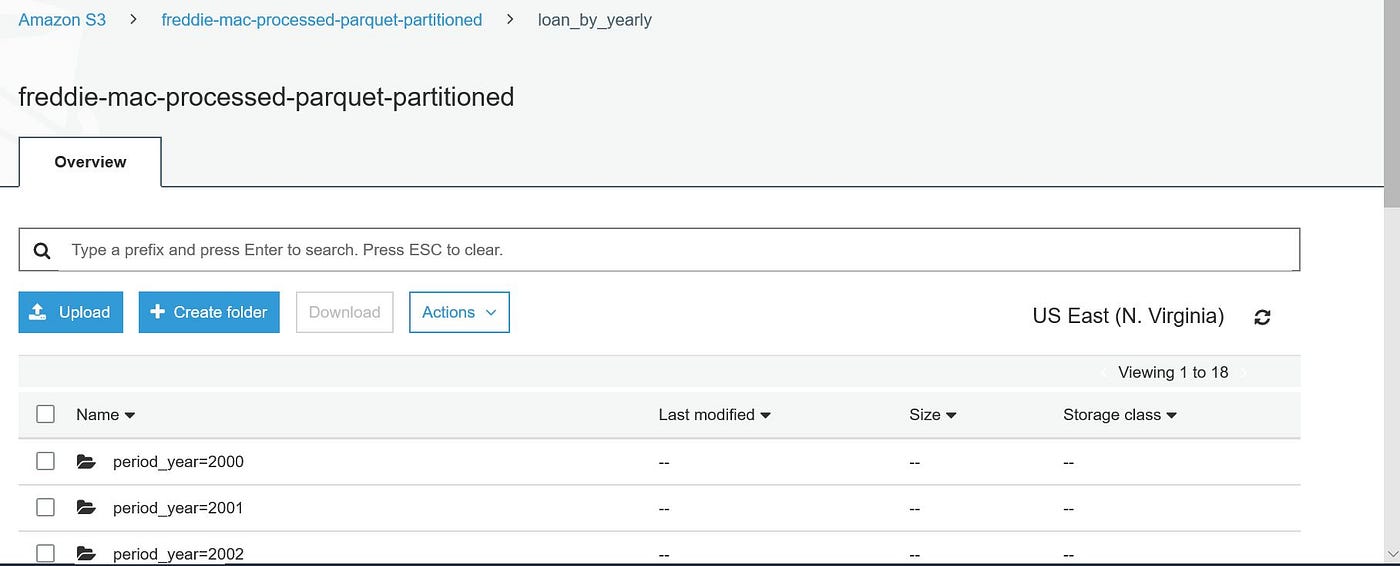
Information is directly copied from EMR hdfs to S3 , to be used later while EMR is launched adjacent fourth dimension.

Later on while a new EMR cluster is launched , a new partitioned tabular array is created using data in S3 location equally below. This is called static segmentation.
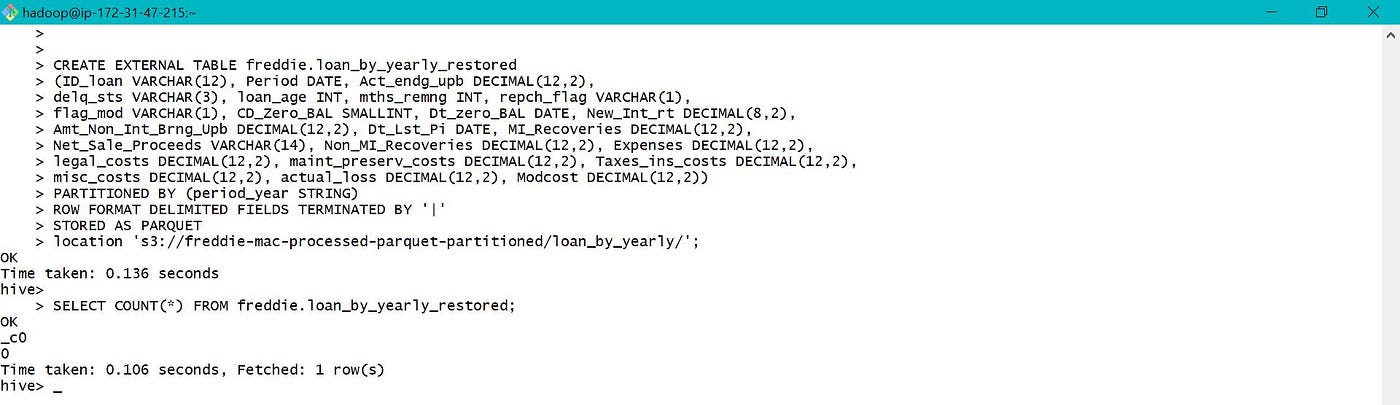
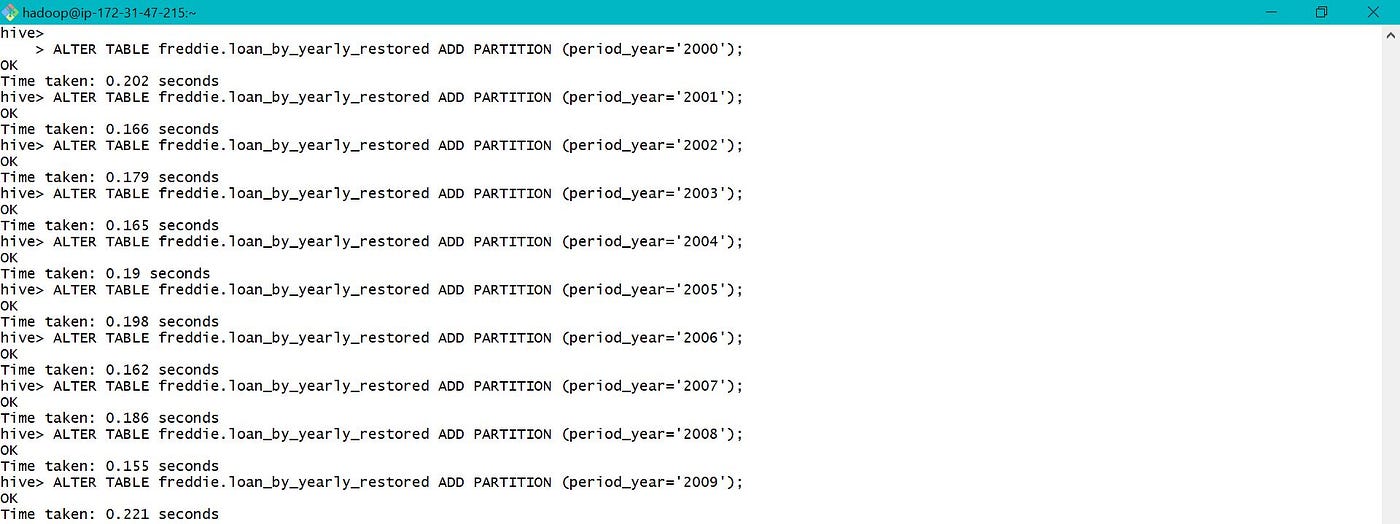
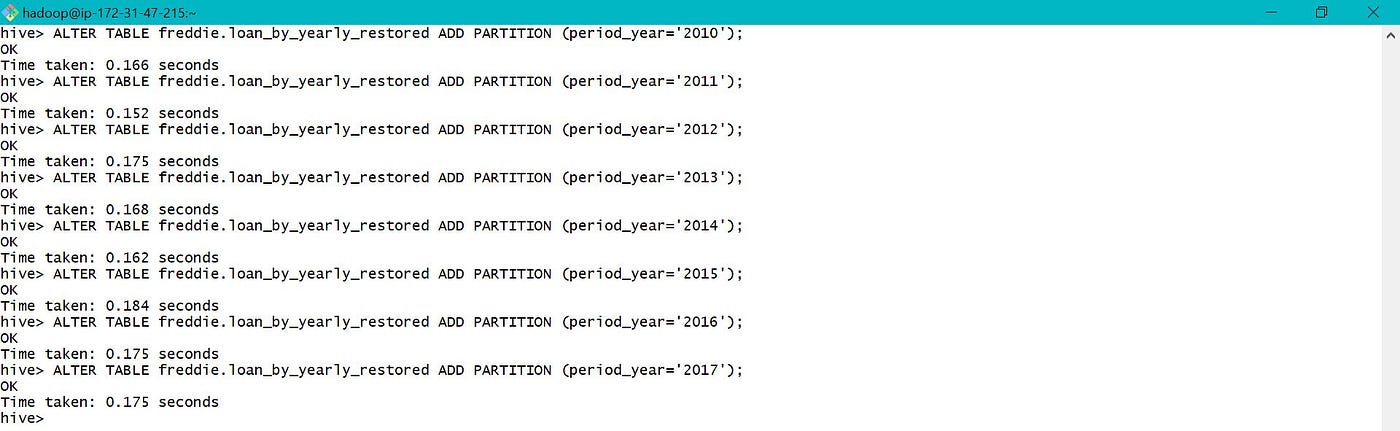
The total count of records in restored partitioned tabular array is equal to the tape count in processed table which is equal to 1064685806 as shown in section 3.
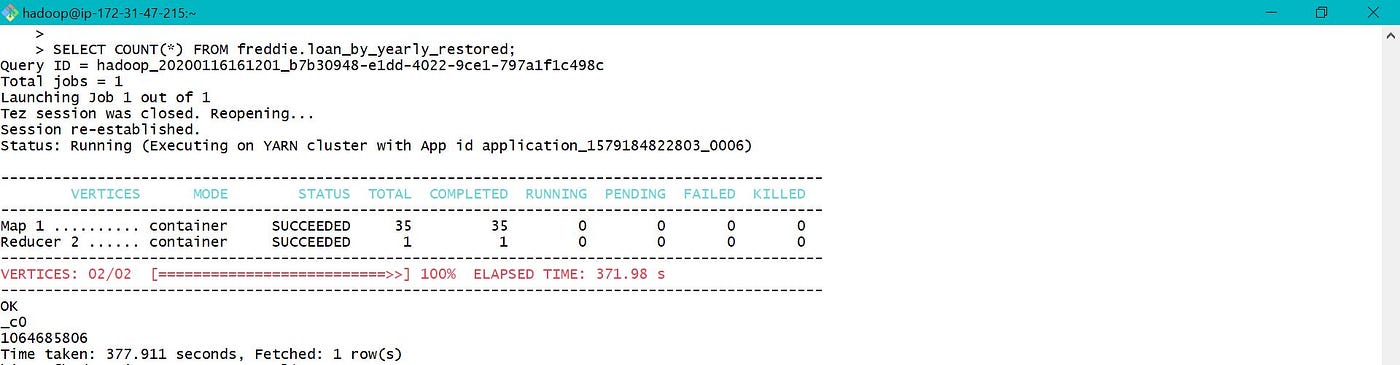
Also from above, total time taken for count in partitioned and not partitioned table is nearly same, every bit sectionalisation is done based on twelvemonth and our count query is not twelvemonth specific.
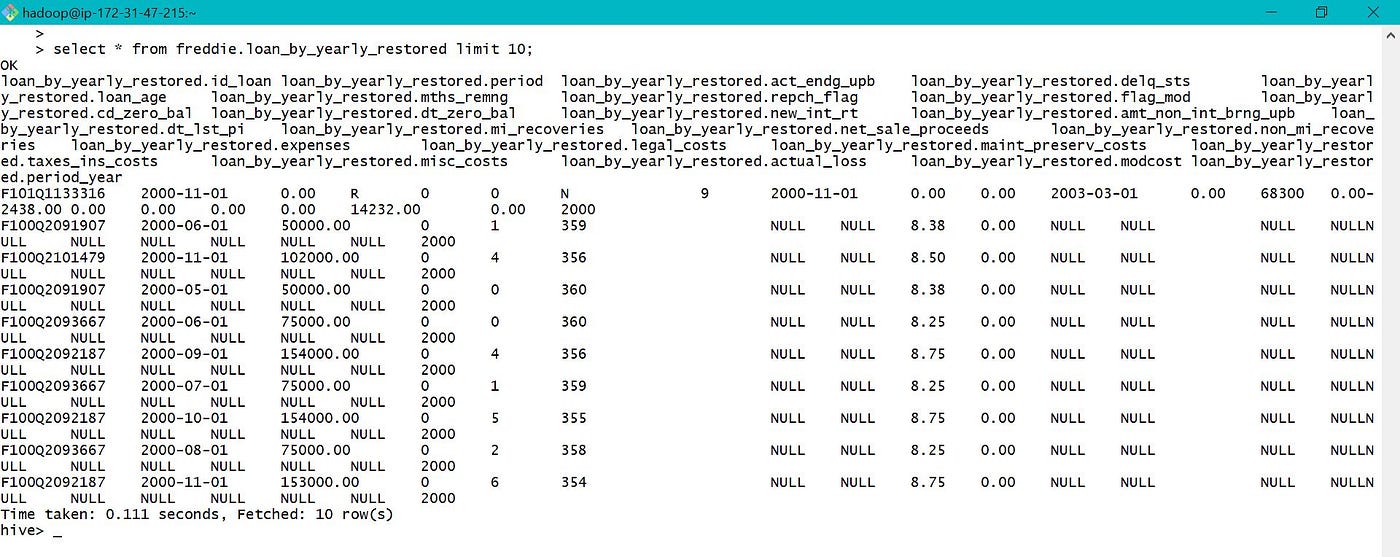
5. Clone an existing table :
Similar can exist used to catalogue or clone an existing tabular array. Here only schema is created and in that location is no data transfer. Data needs to be loaded explicitly to newly cloned table. IF Not EXISTS is used to avert fault while creating new database or tabular array if any older database or table exists with same name.

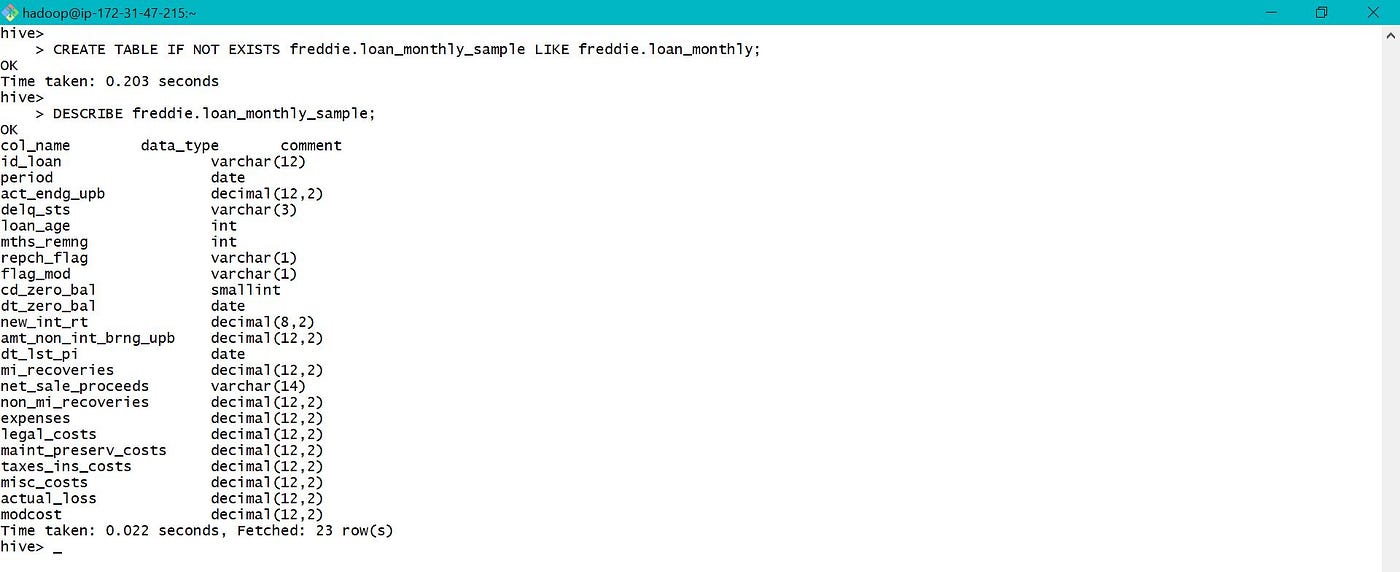

6. Complex and Cord Data Types:
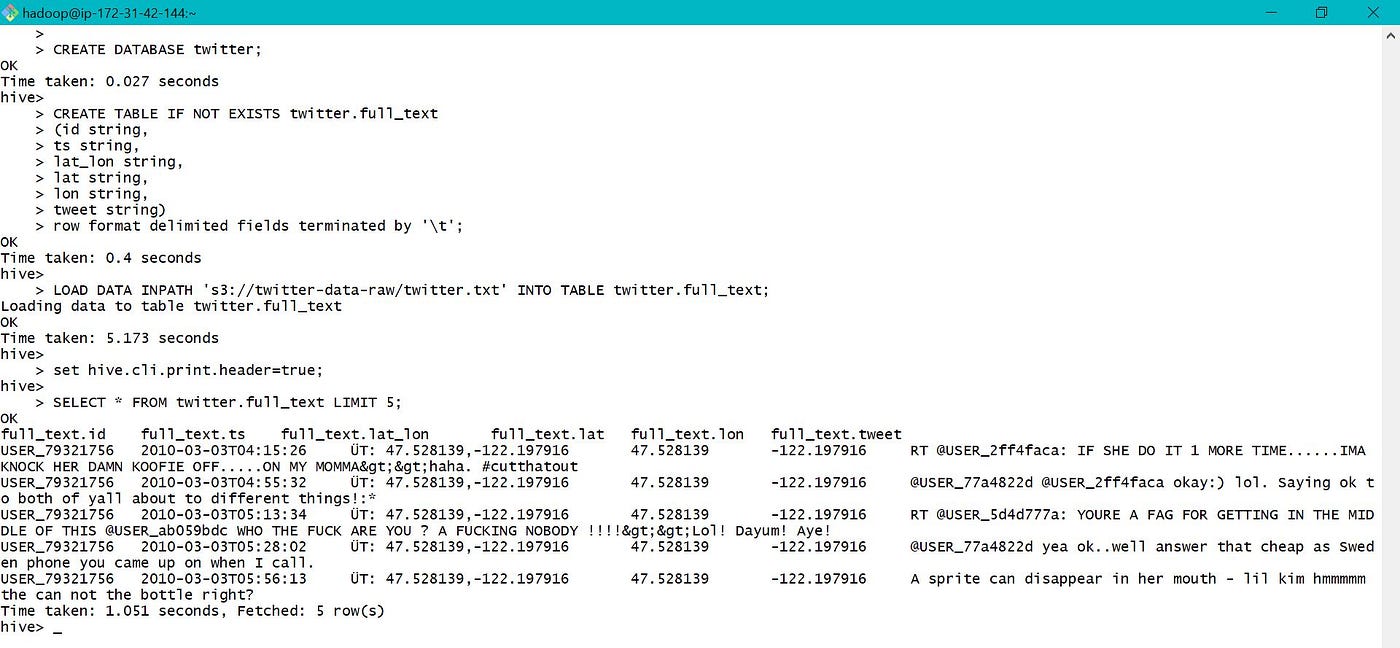
Hive supports complex data types like Array, Map and Struct. Twitter data which was nerveless using Kinesis Firehose has been stored in S3. This information is used to demonstrate Create tables, Load and Query complex data.
Create an temporary table in hive to access raw twitter data. Data tin also be loaded into hive table from S3 as shown below. Using LOAD control, moves(non copy) the information from source to target location.
Create complex data in a temp table by processing cord data equally beneath. If different complex data types are used in same table, all of them must utilize the aforementioned terminator. Hither "|" is used as terminator in array, map and struct.


Create a table with complex data types and re-create processed data to circuitous table data folder. Collection ITEMS TERMINATED BY '|' is used in table definition as information was created accordingly in previous pace.



Complex data is accessed from hive tables as shown below.

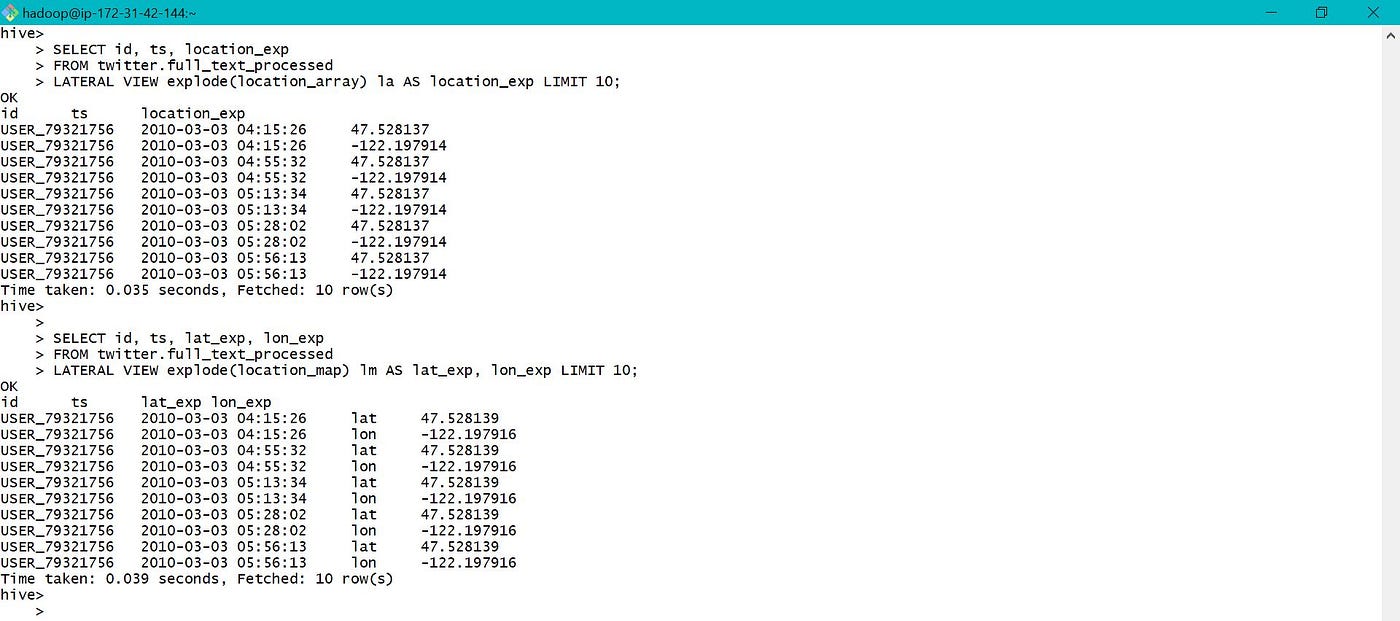
Explode function can also exist used to access only Array and Map as shown below.

When using explode function along with other columns, Lateral View needs to be used as below. Though the words la and lm are not used anywhere, merely needs to exist defined with Lateral View.
7. Working with Views :
A view is an saved query which tin can be queried similarly as a table. If a complex query is used again and again, it can exist saved as a view to save time. View is visible every bit table in database.
Not materialized view are created by default in hive, which does not relieve underlying query data. Operations of view are merged with operations in our external query onto single set up for optimization by hive before execution. But in materialized view, query information is saved to database making them faster. Hence with change of underlying data, non materialized view is updated automatically while materialized view needs to be rebuild.
Society By being an expensive operation, should never be used inside view. If required, sorting should e'er exist included in action performed on view.
Create table dayofweek from data present in S3.



Non materialized and materialized view were created using the processed and day of week data equally shown below. View creation fourth dimension is quick for non materialized view while query time is quick for materialized.
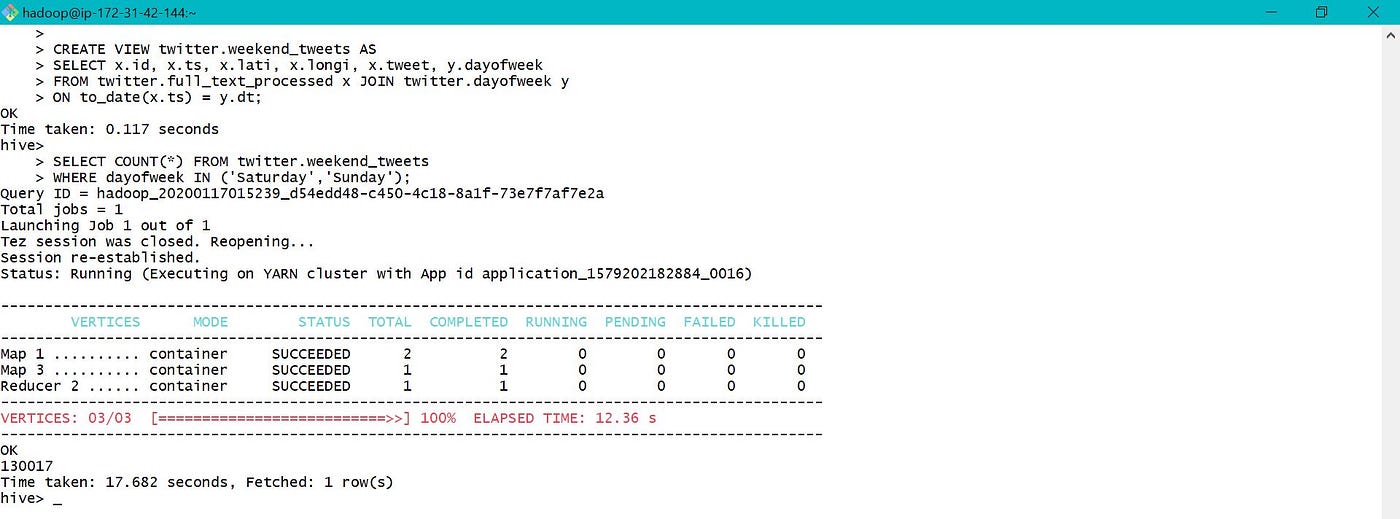
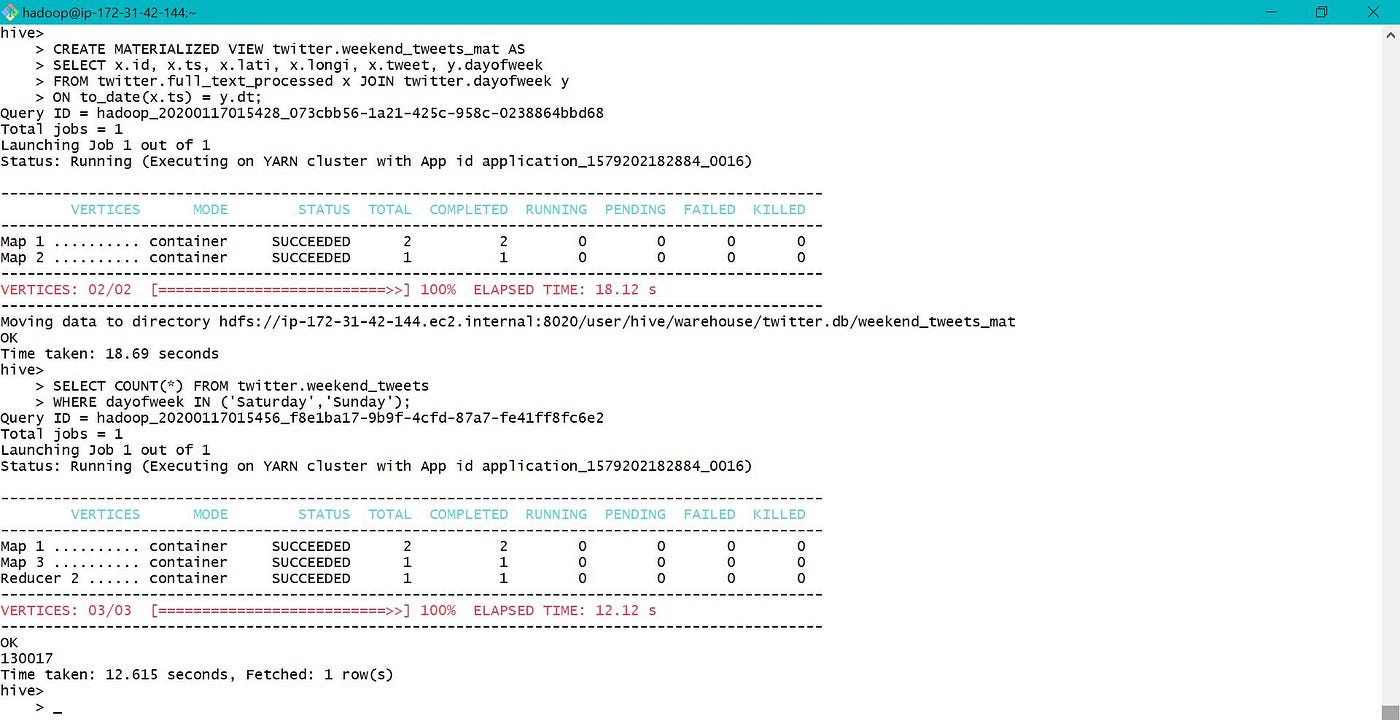
Both the views are visible as tables in database, but data folder is only created for materialized view.


View tin also be modified similarly equally tables depicted beneath.
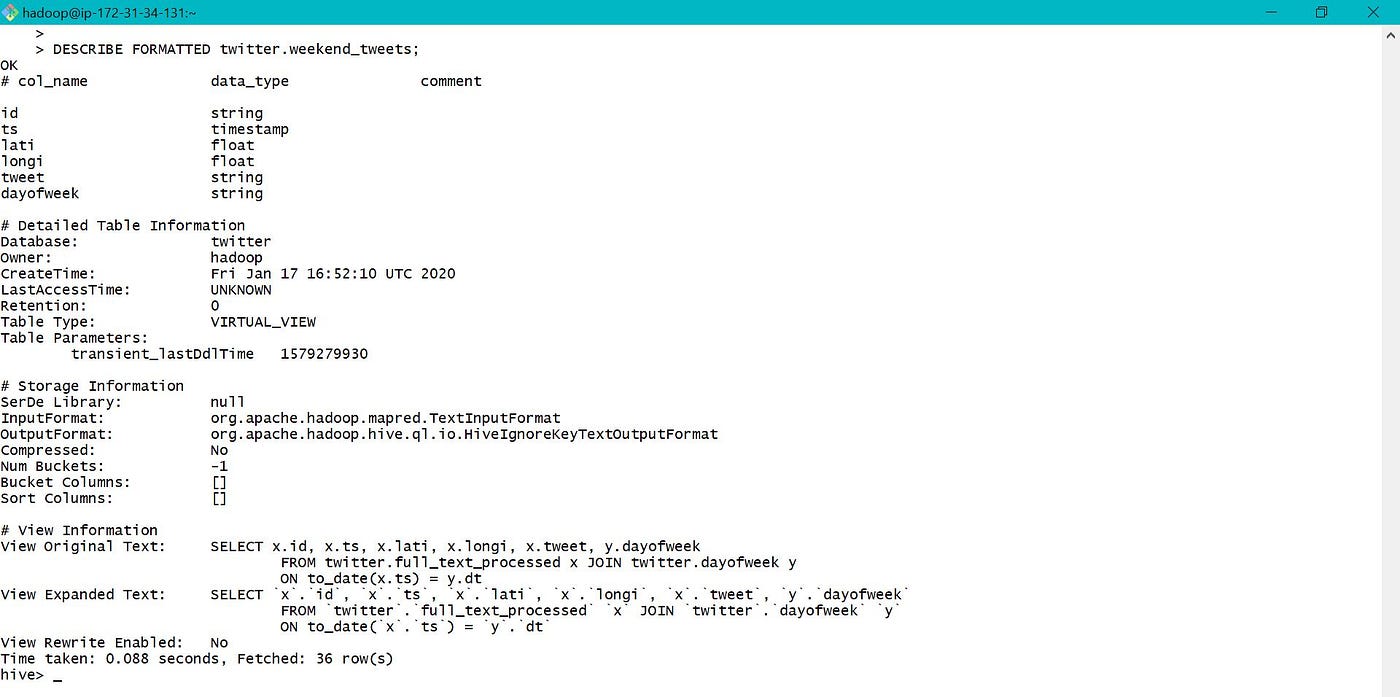

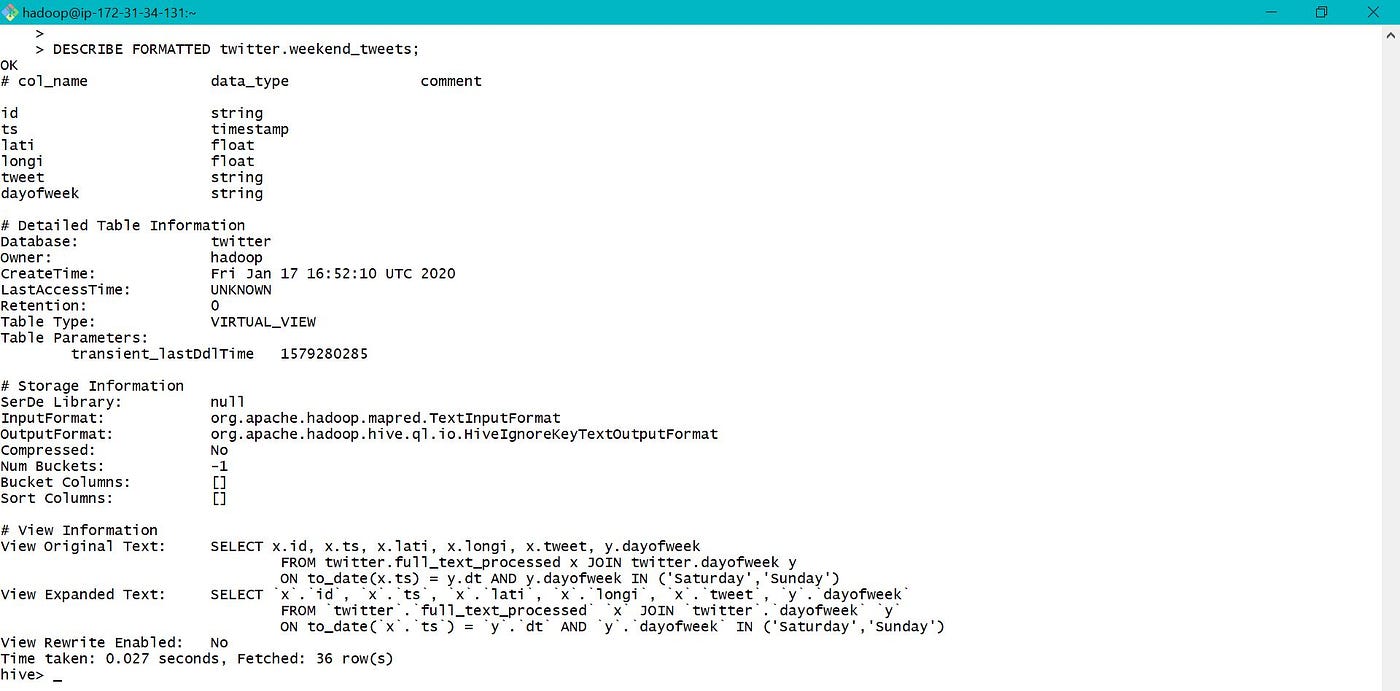

8. Bootstrap during launch of EMR cluster:
Hive queries can be saved to S3 and the aforementioned script location tin can exist used in bootstrap action during launch of EMR cluster. This will execute all the corresponding scripts along with launch of cluster automatically.
nine. Data transfer between HDFS and RDBMS:
sqoop executed in Linux is used for data transfer between HDFS and RDBMS both for import and export.
More details to be updated. Your thoughts volition be appreciated.
Thanks, Abhi.
Source: https://medium.com/analytics-vidhya/an-introduction-to-hadoop-in-emr-aws-701c7b3c6b34
Posted by: hallsupoettly.blogspot.com
0 Response to "How To Upload Data Into Hadoop Emr Cluster"
Post a Comment